

해당 논문을 리뷰하기에 앞서 이 글은 ‘WINNIE’의 컨셉에 초점을 맞춘 리뷰이기에 AFL이나 Coverage-Guided fuzzer의 기본적인 컨셉에 대한 설명은 제외하였다.
제목은 리뷰지만 리뷰라고 하면 건방인거 같으니 논문 정리 쯤으로 하는걸로..
Introduction
문제점
해당 논문은 먼저 WINNIE도입 이전의 윈도우 퍼징 문제점에 대해 언급한다.
1.
GUI 로드로 인한 overhead(최적화시 약 3exec/sec).
2.
이러한 overhead를 해소하기 위한 하네스 역시 추가적인 코드 작성 노력이 필요.
3.
Unix-like OS들의 fork와 같은 기능의 결여로 인해 빠른 속도의 퍼징이 불가.
WINNIE의 CONCEPT
WINNIE는 앞에서 언급했던 문제점들을 해결하기 위한 다양한 방안을 제시한다.
1.
Binary만을 가지고 Static, Dynamic Analysis 모두 사용해 하네스를 자동으로 생성.
2.
윈도우 시스템에서 Unix-like fork를 구현하기 위해 도움이 될만한 API를 분석.
→ 위에 언급했던 개선 요소로 WinAFL 대비 26.6배 더 빠른 실행 속도와 3.6배 더 많은 베이직 블럭 Search 달성.
BACKGROUND: WHY HARNESS GENERATION?
이 파트에서는 WINNIE가 하네스 generator를 개발하게 된 배경을 설명해준다. WinAFL을 사용하기 위해 하네스를 짜본 사람이라면 이 파트를 읽지 않아도 자동 생성기가 필요한 것에 대해선 이견이 없을 듯 하다.. ㅎㅎ..
A. The GUI-Based, Closed-Source Software Ecosystem
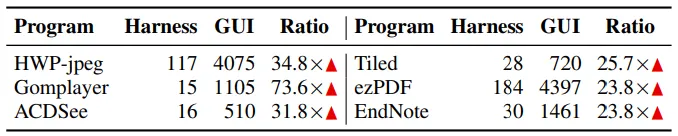
윈도우 프로그램 생태계는 GUI Based로 이루어져 있기 때문에 퍼징 수행에 불리한 점이 있다.
1.
User Interface를 bypass하기 위해서는 해당 프로그램의 코드 베이스에 대한 깊은 이해가 필요하다.
2.
GUI 프로그램은 로드할때 GUI 초기화 시간으로 인해 overhead가 심하다.(위의 TABLE 을 보면 실행속도가 하네스와 비교해 최대 73배까지 차이가 난다.)
B. Difficulty in Creating Windows Fuzzing Harnesses
윈도우 프로그램에 대해 퍼징을 수행할때 하네스를 사용하면 여러가지 장점이 있다.
1.
CLI 기반으로 유저 input을 받을 수 있다.
2.
자원의 낭비를 줄일 수 있다.
3.
2번에서 언급한 이유로 실행속도가 매우 개선된다.
하지만 앞에서 계속 언급했던 closed-source 프로그램이라는 한계 때문에 하네스 작성을 위해 전문가 수준의 높은 리버싱 실력이 필요한 문제점이 있다.
Fudge and FuzzGen
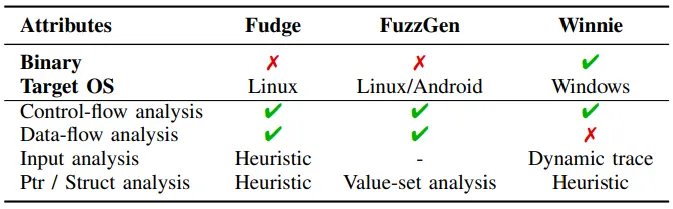
Fudge와 FuzzGen은 오픈소스 프로젝트를 대상으로 하는 하네스 generator이다.
먼저 Fudge는 library를 사용하는 소스코드로 부터 API call 을 추출해 하네스를 생성한다.
반면, FuzzGen은 소스코드의 정적분석을 통해 하네스를 생성한다. 하지만 Fudge와 FuzzGen은 소스코드를 사용할 수 있는 반면, WINNIE의 경우 binary만을 가지고 분석을 수행하기 때문에, 기존의 하네스 생성 솔루션을 사용할 수 없다.
CHALLENGES AND SOLUTIONS
이 파트에서는 기존의 퍼저들이 윈도우 퍼징의 문제점들을 해결한 방식과 각각의 한계를 소개하고 WINNIE가 해당 한계점들을 어떻게 해결 했는지에 대해 설명한다.
A. Complexity of Fuzzing Harness
퍼징 하네스는 우리가 테스트 하고 싶은 함수에 도달하기까지의 모든 Control flow를 똑같이 구현해야 한다. 이를 해결하기 위해 본 논문은 높은 퀄리티의 하네스가 가져야할 4가지 스텝을 제시한다:
1.
target discovery
2.
call - sequence recovery
3.
argument recovery
4.
control-flow and data-flow dependence reconstruction
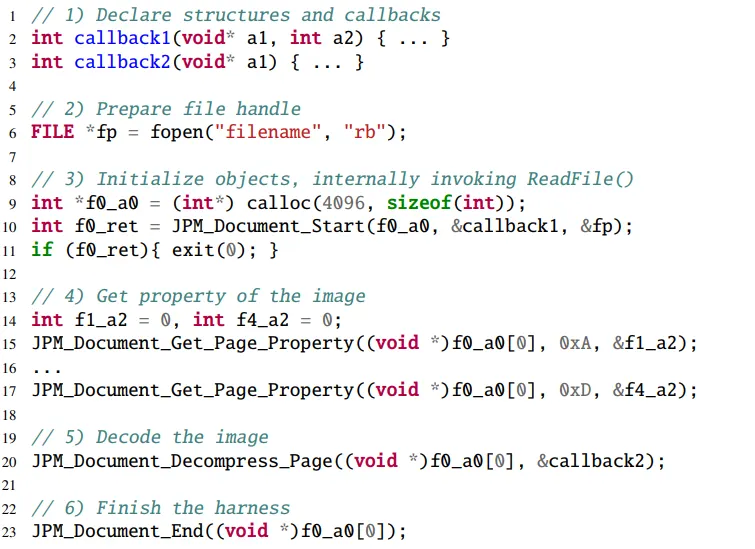
위의 사진은 XnView의 JPM 파서를 대상으로 WINNIE의 generator를 이용해 구성한 하네스인데, 해당 예시로 각 스텝을 설명한다.
1. Target discovery.
퍼징의 첫번째 단계는 유저 input을 핸들링 하는 타겟을 식별하는 것 인데, 이는 여러가지 방법으로 이루어진다.(e.g. filename, file descriptor, file contens, etc.)
위의 예시 프로그램은 file descriptor를 사용한다.
2. Call-sequence recovery.
하네스는 타겟 라이브러리와 관련있는 모든 함수 call을 구현해야한다. 이때 주의해야하는 점은 static 분석만으로는 모든 함수 call을 재구조화 할 수 없을 수 있기 때문에(indirect call and jump table, etc.), dynamic 분석도 함께 진행해야 한다.
위의 예시 프로그램에서는 총 10개의 API call 이 재구조화 되었다.
3. Argument recovery.
하네스는 각 함수 call에 대한 인자를 맞춰주어야 하는데 이때 인자는 integer(like &f1_a2)가 될수도 있고, 콜백 함수(like &callback1)가 될수도 있으며, 상수(like 0xA)등 여러가지 타입이 올 수 있다.
4. Control-flow and data-flow dependence.
특정한 경우에 올바른 순서로 함수들의 call을 정리하는 것 만으로 부족한 경우가 있다. 이런 경우는 Control-flow 디펜던시와 data-flow 디펜던시에서 나타난다.
먼저 Control-flow의 예시는 line 11의 if 분기문이다. 해당 분기가 없으면 올바르게 배치된 API call이 정상적으로 작동하지 않거나, 폰 crash(?)를 감지할수도 있다.
다음으로 data-flow의 예시는 line 10의 f0_a0이다. 해당 변수는 line 15, 17, 20, 23에서도 사용되는 변수이므로 적절히 설정되지 않을경우 프로그램 실행 흐름에 영향을 끼칠 수 있다.
B. Limitations of Existing Solutions
윈도우는 Unix-like OS와 다르게 fork와 같은 클론을 지원하지 않기 때문에 퍼징을 할 때에 많은 자원을 낭비하는 것과 실행 속도가 느리다는 문제점이 있다. 따라서 WinAFL과 같은 윈도우 퍼저들은 persistent mode와 같은 방식으로 해결했다.(같은 프로세스에서 초기화 없이 타겟 함수를 호출하는 방식)
하지만 persistent mode에도 문제점이 있다.(윈도우 버그헌팅은 너무 어렵다...)
1.
프로세스가 초기화 되지 않기 때문에 1KB 메모리 leak같은 작은 버그도 치명적이다.(iteration이 10000이면 10MB leak..)
2.
항상 같은 환경에서 수행되는것이 아니기 때문에, 재현 불가능한 crash가 많다.
3.
callee 함수가 caller 함수에 return을 하지 않으면 퍼징을 수행할 수 없다.
4.
프로그램이 input 파일을 열고있을때 다른 프로세스가 새로운 input 파일을 열 수 없다.
C. Our Solutions
위에서 언급했던 모든 문제들을 해결한 짱짱 갓 퍼저 WINNIE는 두가지 컴포넌트로 구성되어있다.
1.
Harness generator
2.
fork를 지원하는 win-afl 기반 fuzzer

이 그림은 WINNIE의 동작 과정을 나타낸 것 이다. 그림을 바탕으로 WINNIE의 동작 과정을 간단히 설명하자면
1.
타겟 바이너리와 sample input이 주어지면, WINNIE의 tracer가 API call, argument, memory contents와 같은 정보를 수집한다.
2.
이후 수집된 정보를 바탕으로 유저 input을 핸들링 하는 맛집 퍼징 타겟을 추출한다.(이때 범위는 main binary and external library 모두)
3.
harness synthesizer가 추출된 타겟들을 분석해 WINNIE용 하네스로 재구조화한다.
HARNESS GENERATION
이 파트에서는 앞에서 간단히 설명했던 harness generator의 구현에 대해 자세히 설명한다.
A. Fuzzing Target Identification
이 단계에서는 WINNIE가 동적 분석을 수행해 프로그램을 퍼징할 수 있는지 평가하고, 적절한 타겟 함수를 찾는다.

위의 표는 각 실행에서 tracer가 캡처하는 정보들이다.
tracer의 실행 흐름은 다음과 같다.
1.
Module: 로드된 모든 모듈의 base주소를 기록한다.
2.
Call/Jump: 모듈간의 control flow를 변경하는 매 Call 및 Jump마다 현재의 thread id, caller, callee, symbols, arguments를 기록한다.
3.
Return: Return instruction을 수행할때 리턴값을 기록한다.
4.
Arg/Ret Val: 참조할 수 있는 메모리에 없는 값들은 포인터로 취급해 참조된 메모리를 덤프한 후 위의 과정을 반복한다.
이후 harness generator 수집 된 정보들을 바탕으로 퍼징에 적합한 함수를 찾기 위해 다음과 같은 전략을 사용한다.
1.
각 함수 call에서 파일 경로를 가리키는 인자를 찾기 위해 harness generator는 파일 이름을 input 으로 가진다.
2.
이후 알려진 파일 관련 API나 파일 경로를 받는 함수를 찾아 파싱 관련 함수로 판단한다.
WINNIE는 input을 직접 여는 것이 아닌 경우에도(file descriptor, in-memory buffer) call 되는 모든 포인터의 값을 조사해 input과 조금이라도 같은 내용을 가지는 참조된 메모리가 있는지 확인한다.
다음으로 WINNIE는 call-graph 분석으로 main binary 탐색을 확장하는데, I/O 함수와 이전에 기록했던 파싱 라이브러리 API의 LCA(lowest common ancestor)에서 부터 시작한다.
→ 가장 낮은 공통 노드를 찾기 위함인 듯하다.
이때 LCA는 두가지 충족 조건을 가지는데
1.
퍼징 프로세스가 input을 열어도 계속 수정할 수 있도록 file-read 이전이어야 한다.
2.
파싱 함수를 작동시킬 수 있어야한다.
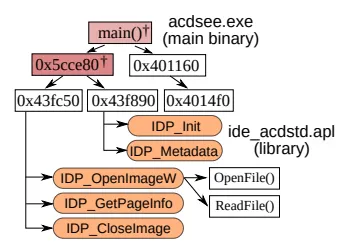
위의 사진은 ACDSee라는 뷰어의 main binary call-graph인데, 0x5cce80 주소의 함수는 파일 관련 API와 핸들 함수의 LCA이면서 충족 조건을 만족한다. 만약 LCA가 충족 조건을 만족하지 않는 경우 LCA의 조상(여기서는 main)을 fallback 함수로 지정한다.
(역시 알고리즘 공부를 해야한다..)
B. Call-sequence Recovery
이전 단계에서 적절한 퍼징 타겟 함수들을 구했으니 타겟까지의 API call을 reconstruct 하는 단계이다.
이러한 API sequence를 harness skeleton 이라고 부른다.
1.
위의 tracer의 정보 중 라이브러리와 관련된 함수 call을 harness skeleton에 복사한다.
2.
이후 IDA Pro나 Ghidra 스크립트를 이용해 harness skeleton을 재구조화 한다.
3.
하네스의 작동을 위한 함수들을 추가한다(main, open files, etc.)
만약, 어플리케이션이 멀티 스레드를 사용하면 파일 관련 API를 호출하는 함수만을 고려하여 Call-sequence를 구성한다.
(tracer는 각 thread id를 기록하므로 스레드 별 분석이 가능하다(만약 모든 스레드에 대해 trace를 했다면 Call-sequence에 엄청난 overhead가 걸렸을듯.)
C. Argument Recovery
이번 단계에서는 함수 인자들을 reconstruct한다.
먼저 포인터 인자를 식별하는데, ASLR이 켜져있으면 각 실행마다 포인터 인자가 다른 주소값을 갖는것을 이용한다. 인자가 포인터인 경우, tracer가 가지고있는 concrete memory contents를 이용해, 다중포인터 여부 등을 판단하여 인자를 정한다.
다음으로 인자가 static인지 변수인지를 판단하는데, 함수 call 사이에서 값이 변하지 않으면 간단히 상수로 취급하여 지정한다.
D. Control-Flow and Data-Flow Reconstruction
•
Control-Flow: API call들이 논리적으로 연결된 관계(e.g. if statement)를 나타내는데, invoke된 함수의 리턴값을 비교해 path를 찾은 뒤에 정적분석된 코드를 복제한다.
→ 이때 너무 복잡한 Control-Flow는 복제하지 않고, 사용자가 직접 짜야하는데 이는 잘못된 Flow 생산으로 재현 불가능한 폰 crash로 이어질 수 있기 때문이다.
•
Data-Flow: 함수 인자와 리턴값의 관계를 나타내는데, call site 사이에서 여러번 사용되는 변수를 찾는다. 이때 아래의 세가지 case를 고려한다.
◦
Simple flows from return values: 항상 이전 함수의 리턴값과 같은 값을 가지는 인자를 찾느다.(만약 0 과 같은 값으로 매우 빈번하게 연결되면 하네스가 잘 못 짜여졌을 수 있다.)
◦
Points-to relationships: 이전 함수의 리턴값이 포인터이고 해당 포인터가 가리키는 값이 인자로 사용될 경우 포인터 역참조를 지원한다.(다중 포인터도 마찬가지이다.)
◦
Aliasing: 상수가 아닌 같은 값을 가지는 두개 이상의 값이 반복적으로 사용되면, 변수로 지정한다.
E. Harness Validation and Finalization
WINNIE는 자명한 솔루션이 아니다. 따라서 생성된 하네스를 검토 및 개선하는 과정을 거친다.
1.
Report distant API calls: 만약 특정 함수 call 사이의 거리가 길면 logic이 깨졌을 수 있다.
2.
Highlight Code pointer argument: 콜백함수를 가리키는 포인터를 알려준다.
3.
Information about File Operation: 하네스 구성에 중요한 요소인 file operation을 알려준다.
이후에 하네스가 완성되면 3가지 검증을 거치는데
1.
정상적인 input으로 crash가 발견되는지 테스트한다.
2.
새로운 코드커버리지에 도달하는지 테스트한다.
3.
실행 속도를 테스트한다.
→ 최종적으로, 이 중 가장 빠른 실행속도를 가지는 하네스를 제공한다.