

Introduction
먼저 이 글을 쓰게 된 배경은 teamH4C에서 브라우저 스터디를 진행하게 되어서 무작성 v8 소스코드 오디팅을 했는데, 구조가 하나도 이해되지 않았다 .. 따라서 브라우저의 JS 코어(특히 v8)의 기본적인 작동 방식에 대해 알아보고 본격적인 오디팅을 진행하기 위해 이 글을 작성하게 되었다.
따라서 브라우저의 JS 코어(특히 v8)의 기본적인 작동 방식에 대해 알아보고 본격적인 오디팅을 진행하기 위해 이 글을 작성하게 되었다.
따라서 브라우저의 JS 코어(특히 v8)의 기본적인 작동 방식에 대해 알아보고 본격적인 오디팅을 진행하기 위해 이 글을 작성하게 되었다.1. Engine, Runtime and Call stack
JavaScript Engine
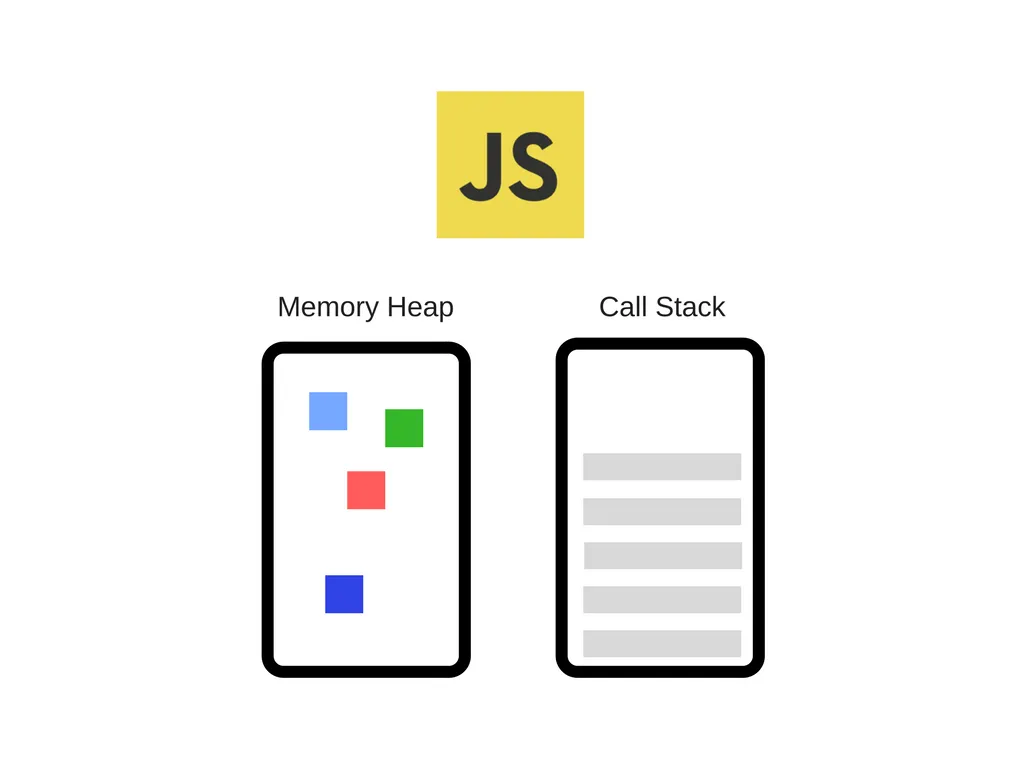
자바스크립트 엔진은 두 가지 요소로 구성된다.
•
메모리 힙 - 메모리가 할당되는 영역.
•
콜 스택 - 스택프레임이 할당되는 영역.
Runtime
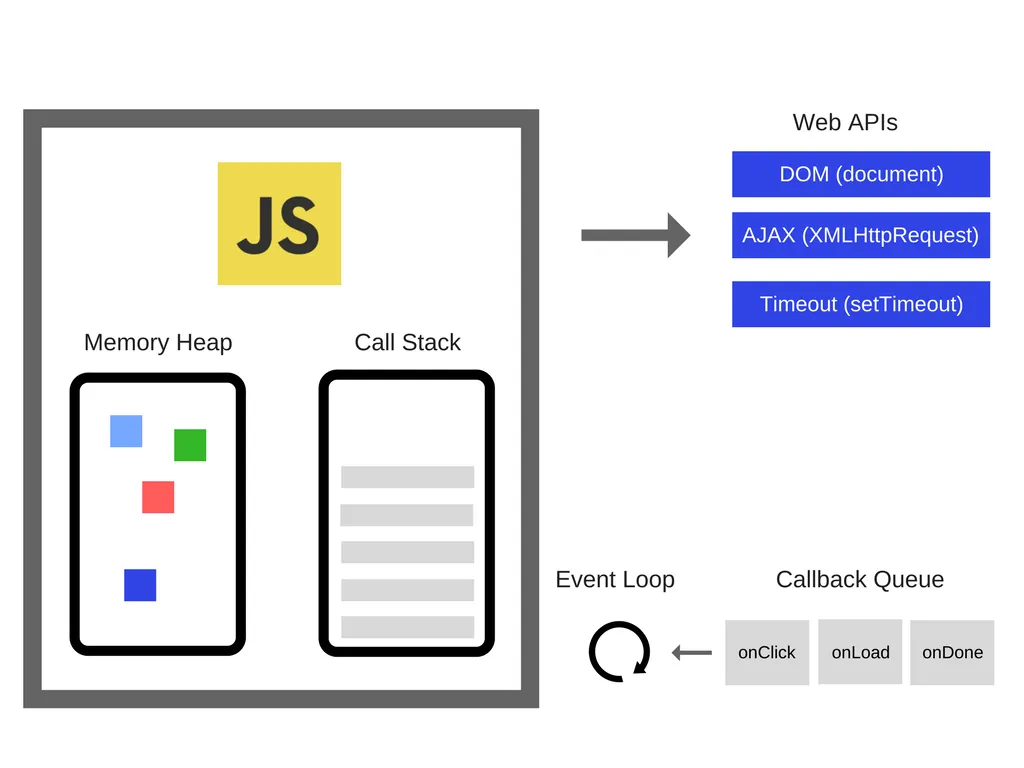
브라우저에는 많은 개발자가 사용하는 JS API가 있는데(ex. setTimeout) 이것은 엔진에서 제공해 주는것이 아니다. (자세한 내용은 후에 다루도록 하겠다.)
Call Stack
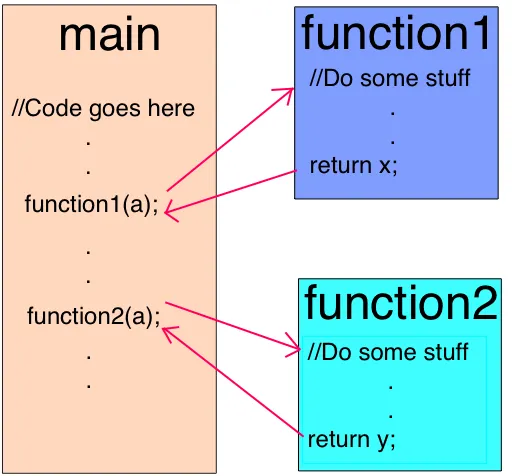
JavaScript는 싱글 스레드 프로그래밍 언어이기 때문에 단일 콜스택을 가진다.
콜스택은 기본적으로 프로그램 안에서 우리가 어디에 있는지 기록하는 데이터 구조이다. 함수에 entry에서 push하게 되고 exit에서 pop한다.
다음 예시코드를 보자:
function multiply(x, y) {
return x * y;
}
function printSquare(x) {
var s = multiply(x, x);
console.log(s);
}
printSquare(5);
JavaScript
복사
해당코드를 실행하면 콜스택은 다음과 같을 것 이다:
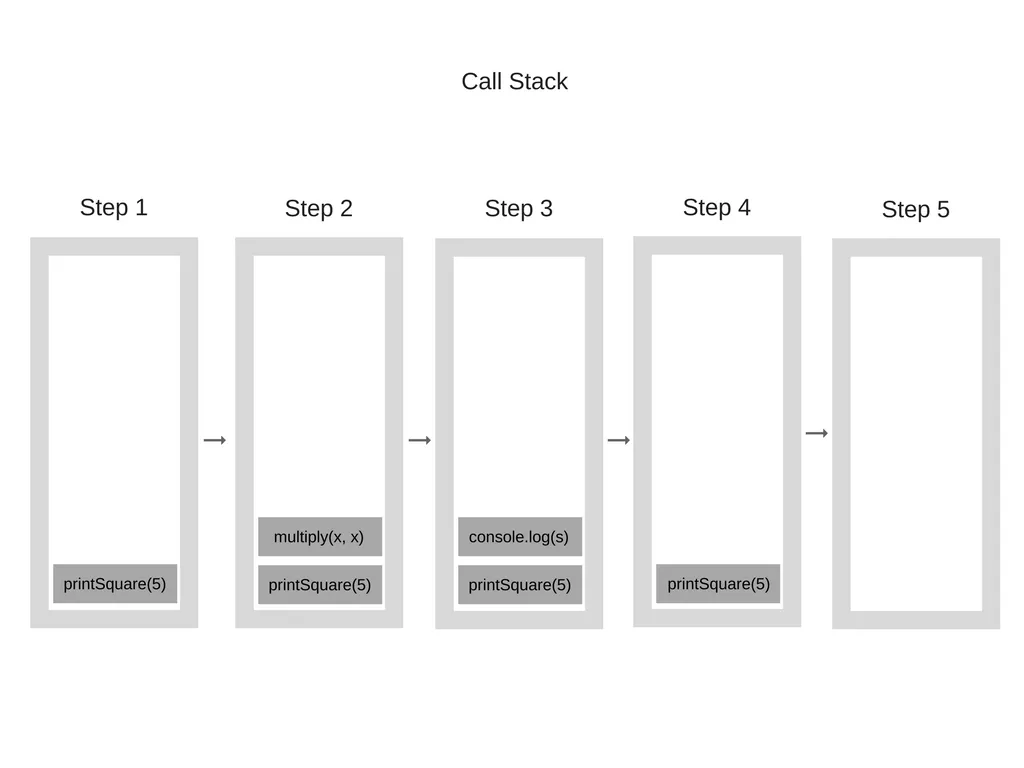
step0에서 비어있는 콜스택에 호출되는 함수가 순서대로 콜스택에 push되는것을 확인할 수 있다.
이때 각 콜스택의 entry는 Stack Frame이라고 부른다.
Stack Trace
만약 JS코드에서 exception 이 발생했을 경우에 해당 콜스택 정보를 이용해 stack trace 정보를 보여주게 된다.
function foo() {
throw new Error('SessionStack will help you resolve crashes :)');
}
function bar() {
foo();
}
function start() {
bar();
}
start();
JavaScript
복사
만약 해당 코드를 chrome 콘솔에서 실행하게 되면 아래와 같은 stack trace가 생성된다.

Blowing the stack
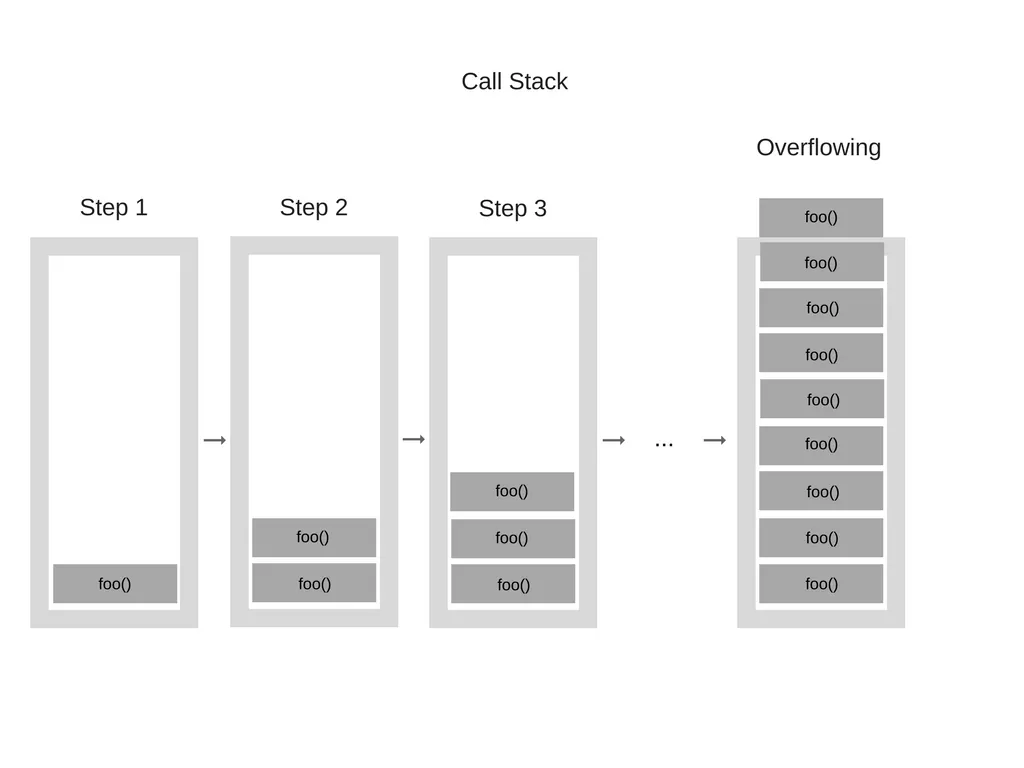
다음 코드에서 같이 재귀 호출과 같은 이유로 함수를 여러번 호출하게 되면 같은 함수가 콜스택에 계속 추가되게 되는데, 만약 호출 횟수가 콜스택 크기를 넘어가게 되면 v8에서는 RangeError를 throw하게 된다.
function foo() {
foo();
}
foo();
JavaScript
복사
Concurrency & the Event Loop
만약 콜스택에 처리할 함수 중 처리하는데 상당한 시간이 걸리는 함수가 있을경우 많은 문제가 생길것이다.
이 함수는 싱글스레드로 처리되기 때문에 페이지 렌더링, 다른 코드 실행등 다른작업이 불가능해지기 때문에 브라우저는 응답을 하지 않을것이며, 브라우저는 응답없음 error를 throw 할 것이다.
따라서 이에대한 해결책으로 비동기 콜백을 사용한다(역시 자세한 내용은 후에 기술한다).
2. Inside The V8 Engine
Google에서 개발한 V8엔진은 오픈 소스이며 내부 구현은 C++로 개발되었다. 해당 엔진은 기본적으로 Chrome 내부에서 사용되며, Node.js 런타임과 같은 다른 응용프로그램 내부에서도 사용된다.

V8은 속도를 위해 인터프리터를 사용하는 대신 다른 JS엔진처럼(SpiderMonkey, Rhino, JSC, etc.) JIT(Just-In-Time) 컴파일러 를 구현해 JS코드를 기계어로 컴파일한다.
V8 Threads
V8엔진은 또한 내부적으로 여러 스레드를 사용하는데, 각 스레드는 다음과 같다(스레드의 이름은 임의로 작성했다).
•
메인 스레드 : 코드를 가져와 컴파일한 후 실행한다.
•
최적화 컴파일 스레드 : 코드를 최적화하여 컴파일한다.
•
프로파일러 스레드 : 최적화할 메소드를 알려주기 위해 많은 시간을 소비하는 메소드를 찾는다.
•
가비지 컬렉터 스레드 : Sweep할 노드를 처리한다.(mem free, etc.)
이 부분이 버전이 바뀌면서 변경된것 같은데, 레퍼런스를 못찾겠다..ㅠㅠ
V8 Processes
V8에는 다양한 프로세스가 있지만 3가지의 필수 프로세스가 있다.
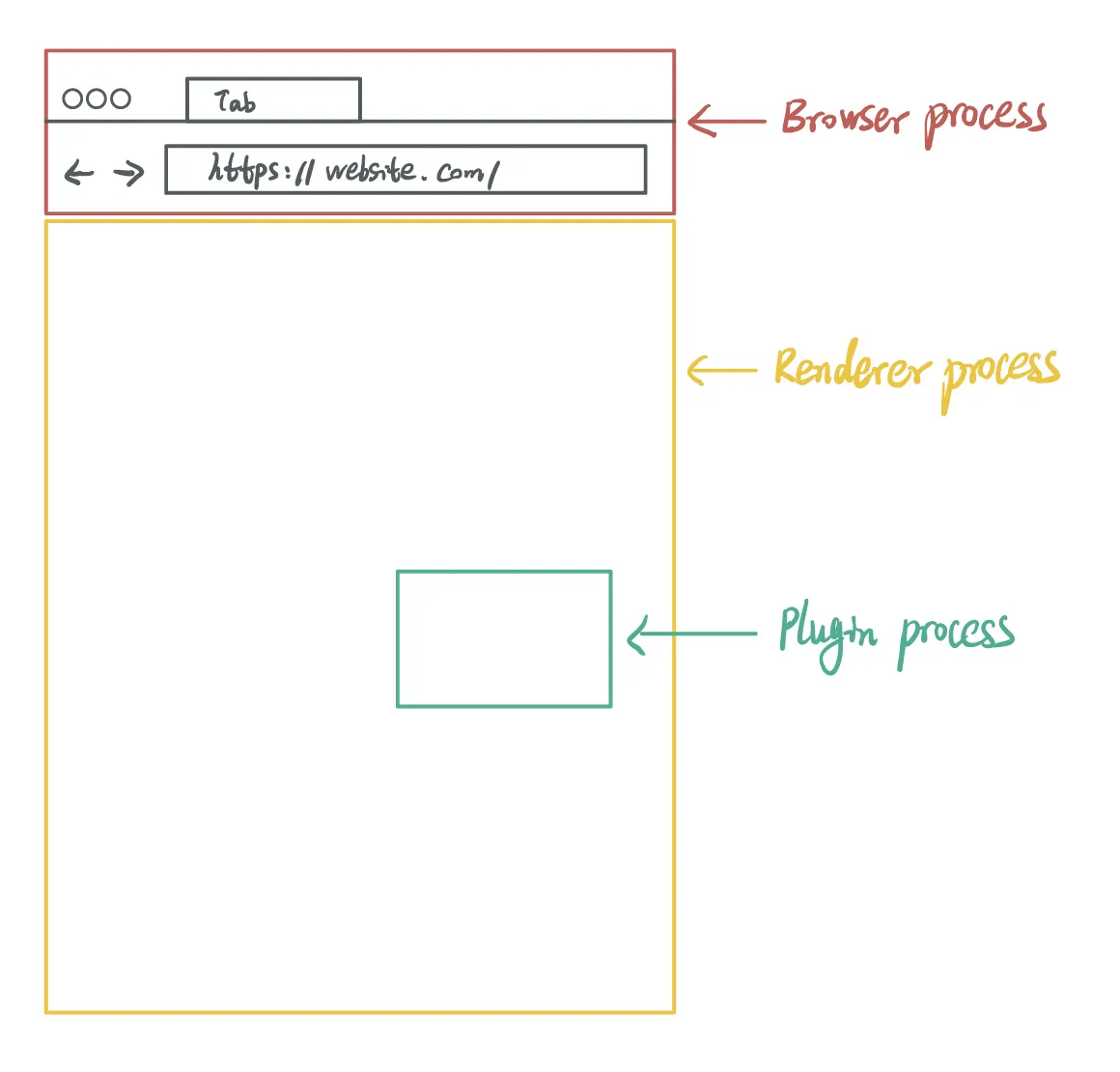
이중 Renderer Process, Plugin Process는 고위험 프로세스(exploitable)로 간주되어 샌드박스에서 실행된다.
V8 compilers(version<5.9)
V8버전 5.9(이때부터 내부 컴파일러 구현의 대대적인 변화가 생김) 전까지는 V8은 두가지 컴파일러를 사용했다.
•
full-codegen : 상대적으로 느린 기계어 코드를 생성하는 간단하고 매우 빠른 컴파일러이다.
•
Crankshaft : 고도로 최적화된 코드를 생성하는 복잡한 최적화 컴파일러입니다.
현재는 사용되지 않는다.
JavaScript 코드를 처음 실행할때 V8은 full-codegen을 활용해 기계 코드를 실행한다.
이후에 코드가 어느정도 실행되면 프로파일러 스레드는 최적화 방법을 알려주기 위한 데이터를 충분히 수집한다.
다음으로 최적화 컴파일 스레드는 Crankshaft를 이용해 JS Abstract Syntax Tree(AST)를 Hydrogen 이라고 하는 high-level static single-assignment(SSA) 표현으로 변환하고 해당 Hydrogen 그래프를 최적화한다.
(AST에 대해서는 후술한다.)
V8 compilers(version≥5.9)
위에서 언급했듯이 5.9버전부터는 컴파일러 파이프라인이 변하게 되었는데 다음 그림으로 비교하면:
# v5.9이전의 구조
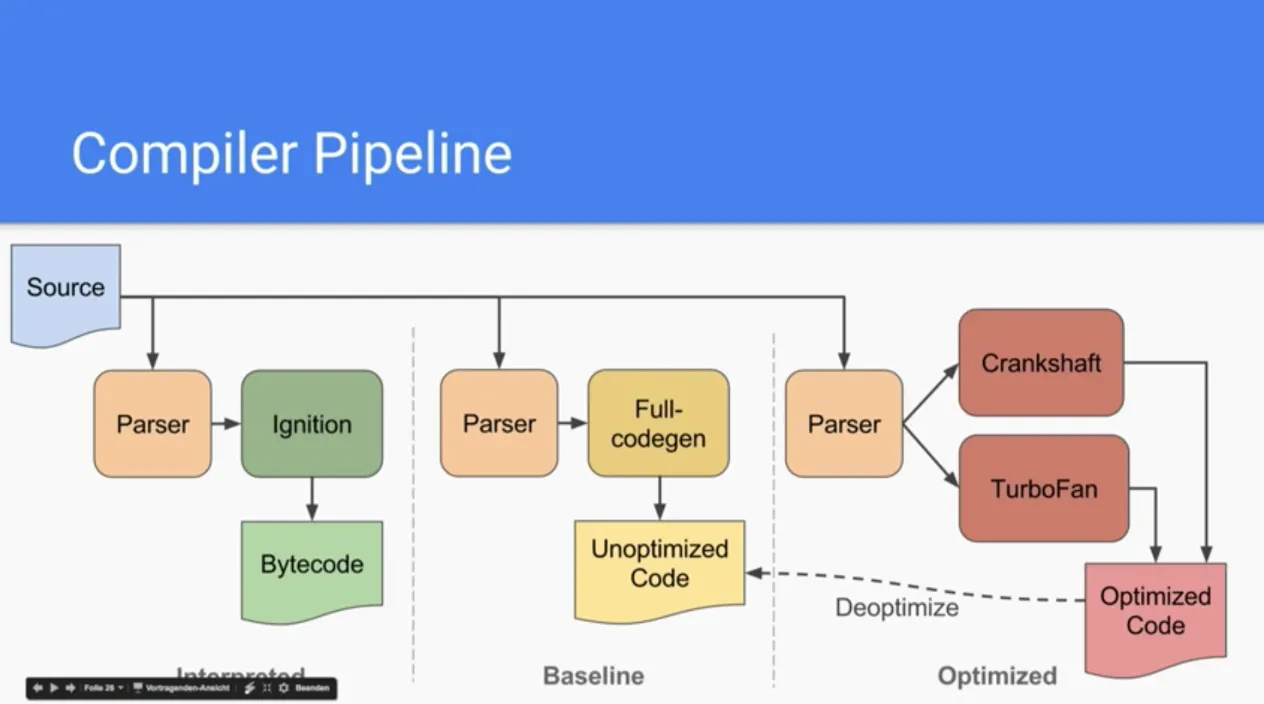
위에서 설명했던 Full-codegen과 Crankshaft 컴파일러가 사용되는 것을 볼 수 있는데,
# v5.9이후의 구조
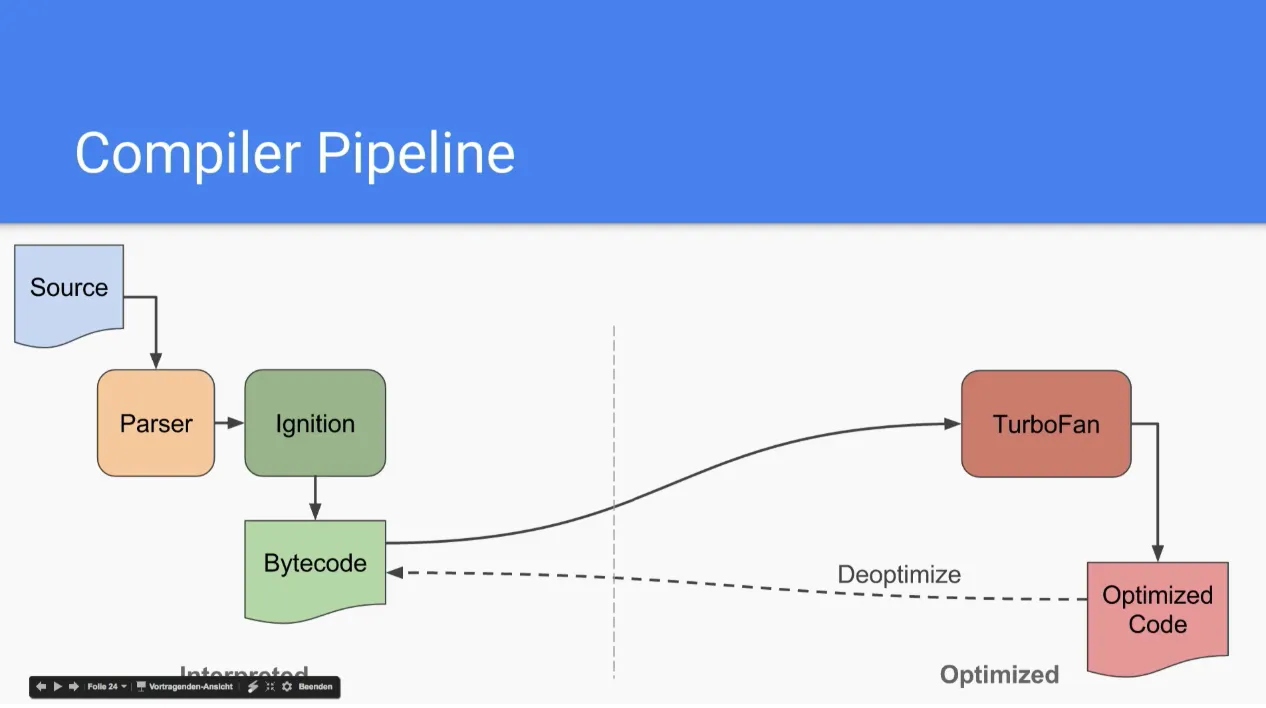
V8 엔진이 계속해서 개선되면서 Ignition과 TurboFan의 성능이 좋아지는것에 반해 Full-codegen과 Crankshaft는 성능이 받쳐주지 못해 이 두가지를 제거했다.
원래 목적이 Ignition과 TurboFan만 사용하려고 했지만 이 둘의 성능이 떨어져서 복잡한 구조를 가지게 되었었다고 한다.
V8 동작과정
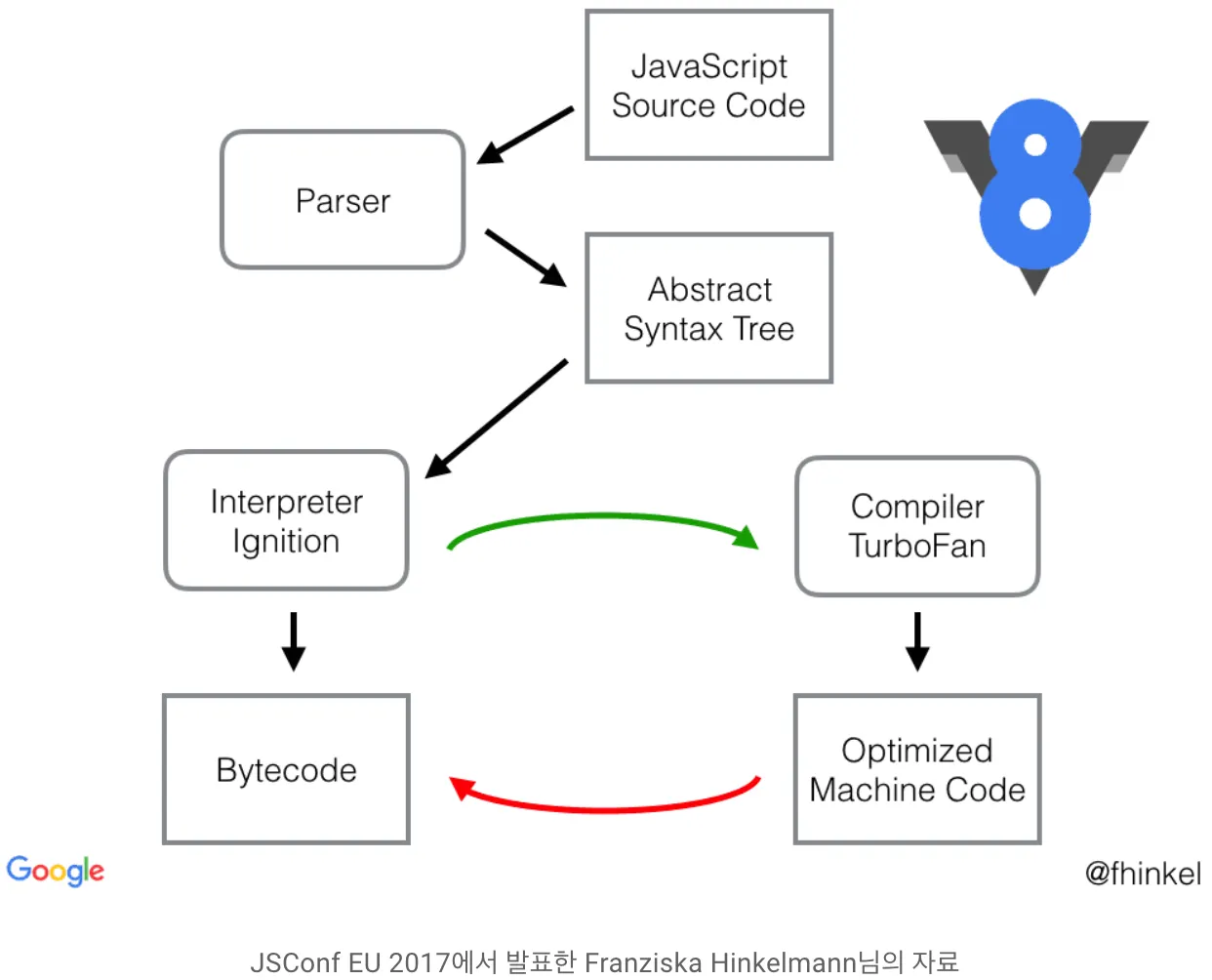
현재의 V8 엔진은 다음 그림과 같은 과정으로 동작하는데 각 과정을 순서대로 설명해보도록 하겠다.
1.
function hello (name){
return 'Hello,' + name;
}
---------------------------------
// AST
{
type: 'FunctionDeclaration',
name: 'hello'
arguments: [
{
type: 'Variable',
name: 'name'
}
]
// ...
}
JavaScript
복사

2.
Ignition 인터프리터는 Parser로 부터 AST를 받아 바이트 코드로 변환한다.

Inlining
인라이닝 최적화는 함수가 호출되는 call site(코드에서 함수가 호출되는 라인)을 호출되는 함수의 구현부로 바꾸는 최적화이다.
Hidden Class
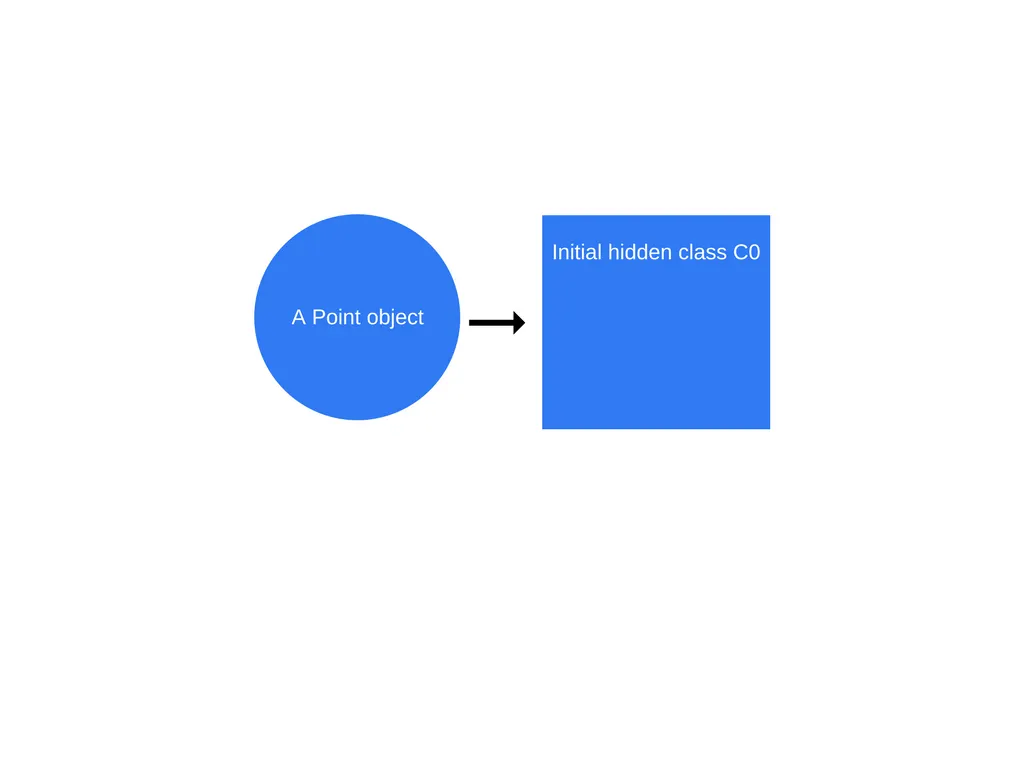
JavaScript는 프로토타입 기반 언어이다. 클래스가 없고 복제 프로세스를 사용해 객체가 생성된다. 따라서 Java와 같은 비동적 언어와 다르게 런타임에 객체 속성을 추가 및 제거할 수 있다.
비동적 언어에서는 속성 값을 고정 오프셋으로 메모리에 연속 버퍼로 저장하고, 객체 속성 위치를 찾기위해 dictionary를 사용한다. 하지만 동적 언어에서는 해당 방식이 매우 비효율적이므로 hidden class를 사용한다.
다음 예시코드의 경우를 보자:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
JavaScript
복사
“new Point(1, 2)”가 호출되면, v8은 “C0”라고 부르는 hidden class를 생성할 것 이다.
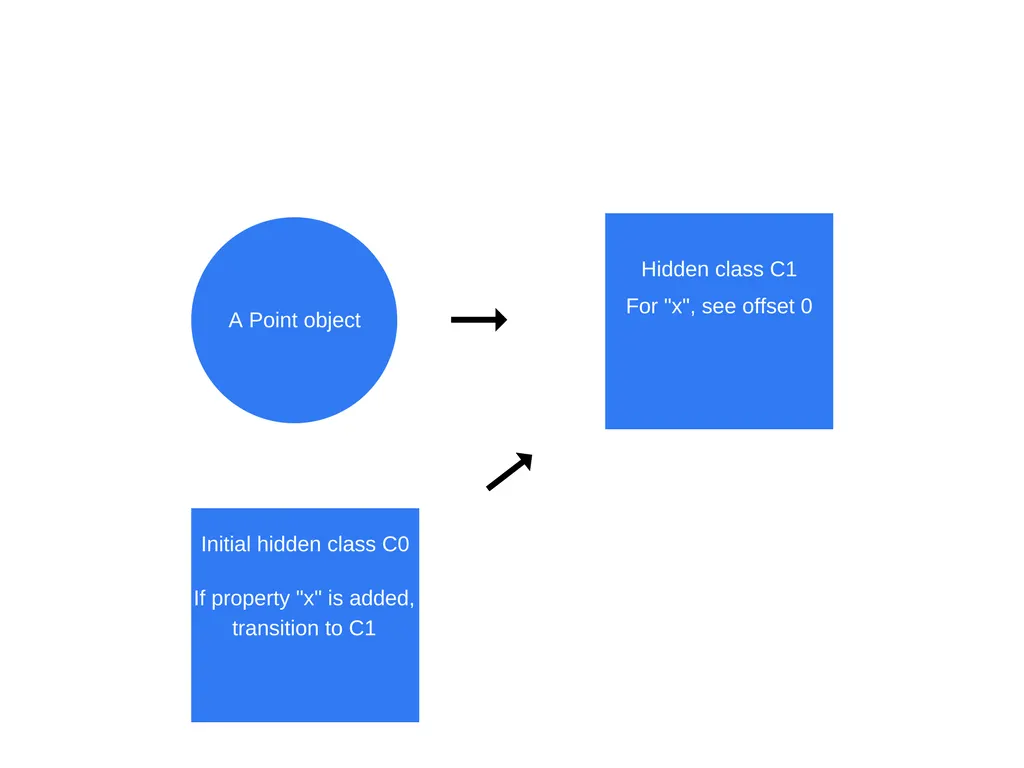
다음으로 "this.x = x"가 실행되면 V8은 "C0"을 기반으로 하는 "C1"이라는 두 번째 히든 클래스를 생성한다. "C1"은 속성 x를 찾을 수 있는 메모리의 위치(객체 포인터 기준)를 나타낸다. V8은 또한 속성 "x"가 Point객체에 추가되면 히든 클래스가 "C0"에서 "C1"으로 전환되어야 한다는 "클래스 전환"으로 "C0"을 업데이트한다.
“this.y = y”가 실행될때도 마찬가지로 같은 과정이 반복된다. “C1” 기반의 “C2” 히든 클래스가 생성되고, “C1”을 클래스 전환으로 업데이트하고 Point객체의 히든 클래스가 “C2”로 업데이트 된다.
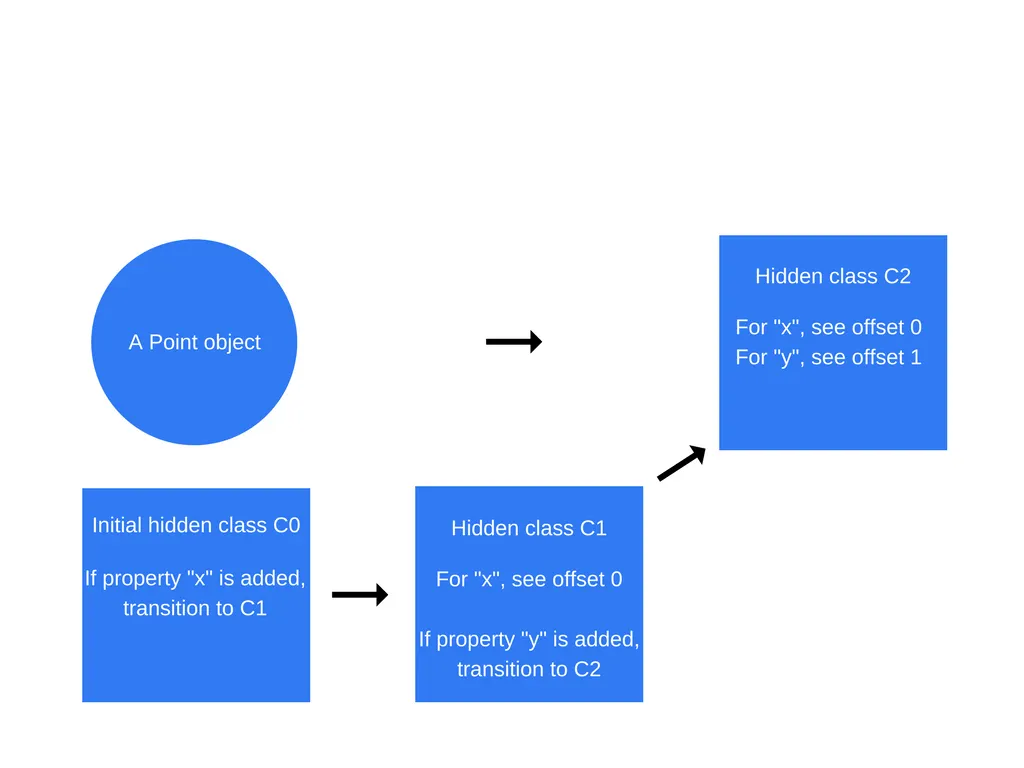
주의해야 할 것은 히든 클래스는 객체의 속성이 추가되는 순서대로 생성되기 때문에 속성을 동일한 순서로 초기화 해야 히든 클래스를 재사용할 수 있다.
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.b = 7;
p2.a = 8;
JavaScript
복사
다음과 같이 속성이 추가되는 순서가 다르면 서로 다른 히든 클래스가 생성된다.
Inline caching
인라인 캐싱은 동일한 메서드에 대한 반복 호출이 같은 유형의 객체에서 발생하는 경향에 의존한다.
즉, 반복문 등에서 객체에 접근할때 객체 속성을 알아내는 프로세스를 우회하고 이전 조회에서 저장된 객체에 대한 정보를 사용한다. (즉 저장된 히든 클래스 정보를 사용한다는 뜻)
3. Parsing & ASTs
다음의 예시로 AST가 만들어지는 과정을 알아보자:
function foo(x) {
if (x > 10) {
var a = 2;
return a * x;
}
return x + 10;
}
foo()
JavaScript
복사
파서는 다음 AST를 생성한다.
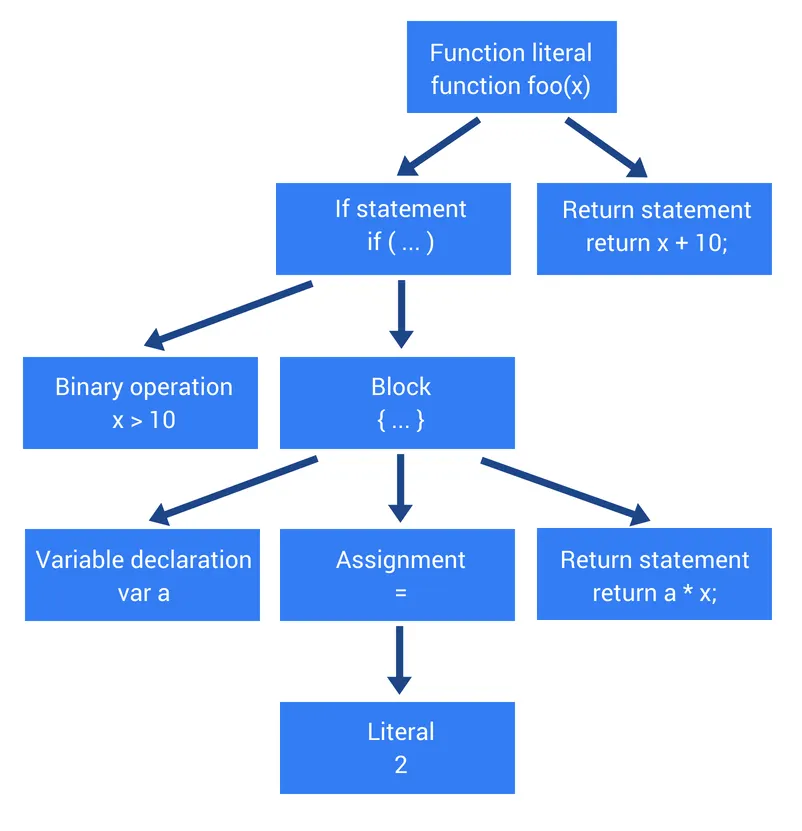
이 그림은 시각화를 위해 파서가 생성한 AST의 단순화 버전이다.
다음은 선언만 된 소스코드의 AST를 알아보자:
function foo() {
function bar(x) {
return x + 10;
}
function baz(x, y) {
return x + y;
}
console.log(baz(100, 200));
}
JavaScript
복사
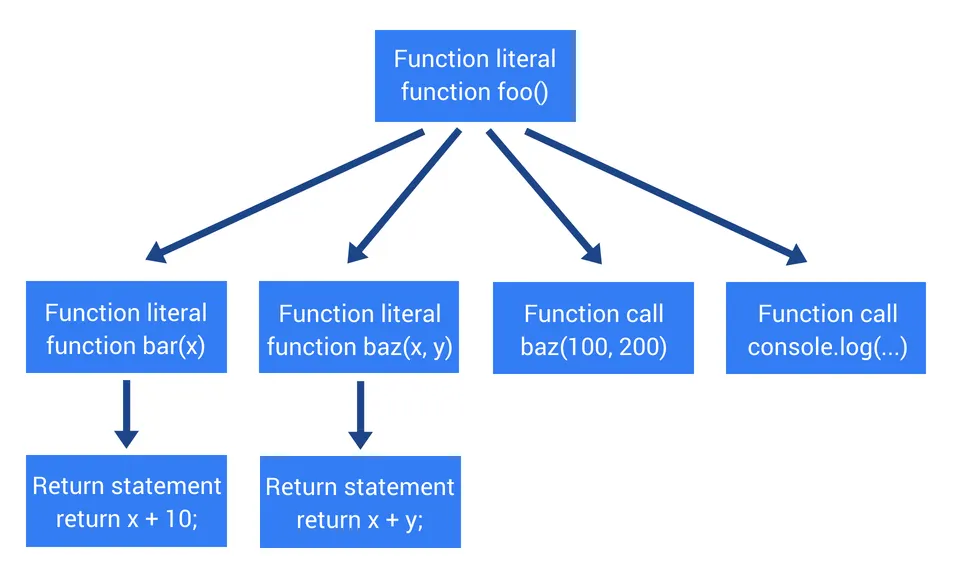
그림과 같이 실제로 호출되지 않은(선언만 된)함수는 구문분석되지 않았다.
4. Memory Management
JavaScript는 c와 같은 low-level언어와 다르게 Garbage Collector를 사용하기 때문에 자동으로 메모리가 할당 및 해제된다. 때문에 메모리 관리와 관련된 문제가 발생할 수 있다.
Memory life cycle
다음 그림은 메모리를 관리하는 3단계를 나타낸다:
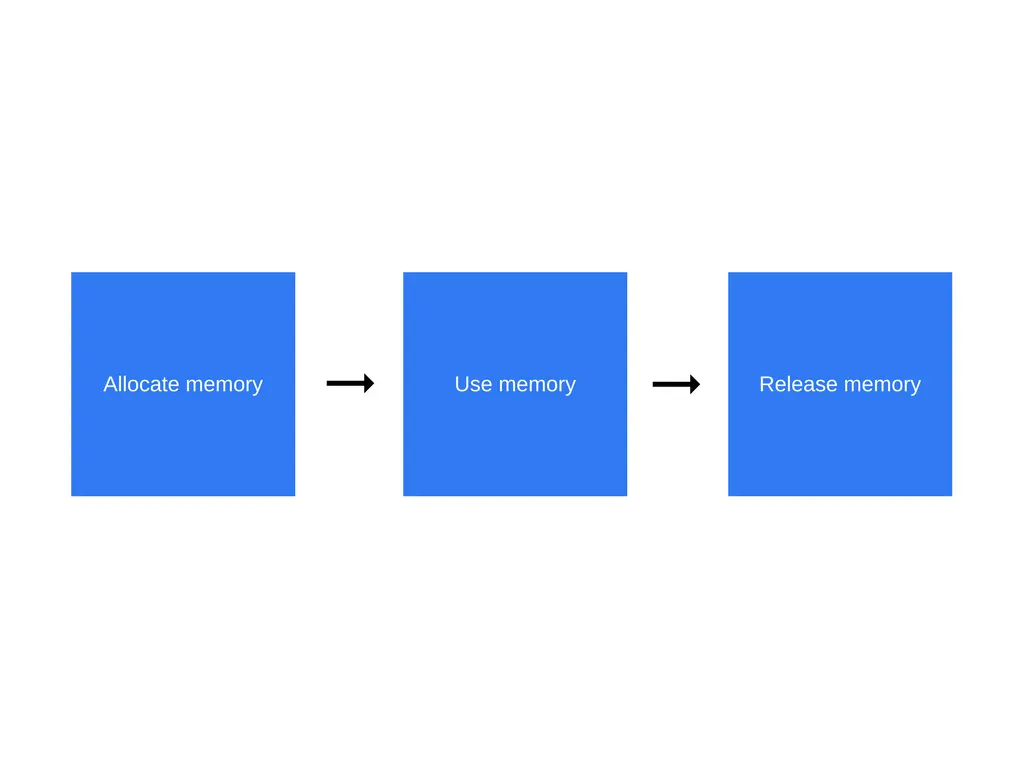
•
Allocate memory : 메모리를 사용할 수 있도록 OS에 의해 메모리가 할당된다.
•
Use memory : 이전에 사용하기 위해 할당된 메모리에 읽기 및 쓰기 작업을 수행한다.
•
Release memory : 필요하지 않은 메모리를 해제해 다시 할당할 수 있도록 한다.
Memory Allocation in JavaScript
var n = 374; // allocates memory for a number
var s = 'sessionstack'; // allocates memory for a string
var o = {
a: 1,
b: null
}; // allocates memory for an object and its contained values
var a = [1, null, 'str']; // (like object) allocates memory for the
// array and its contained values
function f(a) {
return a + 3;
} // allocates a function (which is a callable object)
// function expressions also allocate an object
someElement.addEventListener('click', function() {
someElement.style.backgroundColor = 'blue';
}, false);
JavaScript
복사
var d = new Date(); // allocates a Date object
var e = document.createElement('div'); // allocates a DOM element
JavaScript
복사
var s1 = 'sessionstack';
var s2 = s1.substr(0, 3); // s2 is a new string
// Since strings are immutable,
// JavaScript may decide to not allocate memory,
// but just store the [0, 3] range.
var a1 = ['str1', 'str2'];
var a2 = ['str3', 'str4'];
var a3 = a1.concat(a2);
// new array with 4 elements being
// the concatenation of a1 and a2 elements
JavaScript
복사
다음 소스코드들과 같이 변수선언, 객체선언, 함수호출 등 을 수행할때 메모리 할당이 이루어 진다.
Memory Use in JavaScript
JS에서 할당된 메모리를 사용한다는것은 기본적으로 읽고 쓰는것을 의미한다.
즉, 변수 또는 객체의 속성값 등을 읽고 쓰는것과 같은 방식으로 메모리를 사용할 수 있다.
Release Memory(by Garbage Collector) in JavaScript
JS와 같은 high-level 언어의 Memory management에서 가장 어려운 작업은 할당된 메모리가 필요하지 않은 시점을 파악하는 것 이다.
특히, Garbage Collector는 해당 메모리가 “더 이상 필요하지 않은지”에 대한 여부를 결정 하는것은 불가능하기 때문에, General-problem에 대한 제한적인 해결책만을 구현한다.
Memory references
Garbage Collector가 의존하는 주요 개념은 reference이다.
메모리 관리에 관점에서는 어떤 객체가 다른 객체에 접근이 가능하다면 다른 객체를 참조한다고 한다. 예를 들어 JS객체는 자신의 프로토타입에 대한(암묵적) 참조를 갖고 있으며, 자신의 속성 값에 대한 (명시적) 참조도 갖고 있다.
Reference-counting garbage collection
가장 단순한 형태의 가비지 컬렉션 알고리즘이다.
객체는 그것을 가리키는 참조가 하나도 없을 경우에 garbage collectible 으로 간주한다.
다음 예시 코드를 보자:
var o1 = {
o2: {
x: 1
}
};
// 2 objects are created.
// 'o2' is referenced by 'o1' object as one of its properties.
// None can be garbage-collected
var o3 = o1; // the 'o3' variable is the second thing that
// has a reference to the object pointed by 'o1'.
o1 = 1; // now, the object that was originally in 'o1' has a
// single reference, embodied by the 'o3' variable
var o4 = o3.o2; // reference to 'o2' property of the object.
// This object has now 2 references: one as
// a property.
// The other as the 'o4' variable
o3 = '374'; // The object that was originally in 'o1' has now zero
// references to it.
// It can be garbage-collected.
// However, what was its 'o2' property is still
// referenced by the 'o4' variable, so it cannot be
// freed.
o4 = null; // what was the 'o2' property of the object originally in
// 'o1' has zero references to it.
// It can be garbage collected.
JavaScript
복사
o3 = '374'; 에서 원래의 o1 을 가리키는 참조가 모두 없어졌으므로 o1은 garbage collectible이고, o4 = null; 에서 o3.o2를 가리키는 참조가 없어졌으므로 o2 역시 garbage collectible 이다.
Cycles are creating problems
reference-counting garbege collection 알고리즘을 사용하면 순환 때문에 생기는 제한점들이 있다.
다음의 예를 보자:
function f() {
var o1 = {};
var o2 = {};
o1.p = o2;
o2.p = o1;
}
f();
JavaScript
복사
이 객체들은 f 함수 호출 이후에 실질적으로 쓸모가 없게 되지만 garbage collectible 하지 않다.
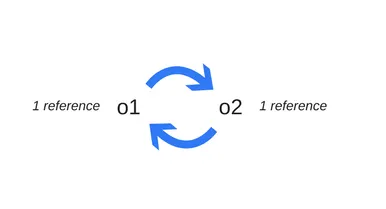
Mark-and-sweep algorithm
이 알고리즘은 해당 객체에 닿을 수 있는지를 판단한다.
다음 세 단계를 거친다:
1.
Roots : 일반적으로 루트는 코드에서 참조되는 전역 변수이다. 예를 들어 자바스크립트에서 루트로 동작할 수 있는 전역 변수는 window 객체이다. 가비지컬렉터는 모든 루트의 완전한 목록을 만들어냅니다.
2.
그런 다음 모든 루트와 그 자식들을 검사해서 활성화 여부를 표시한다. 루트가 닿을 수 없는 것들은 가비지로 표시된다.
3.
마지막으로 가비지컬렉터는 활성으로 표시되지 않은 모든 메모리를 OS에 반환한다.

해당 알고리즘을 사용하게 되면 순환 참조 문제도 해결된다.
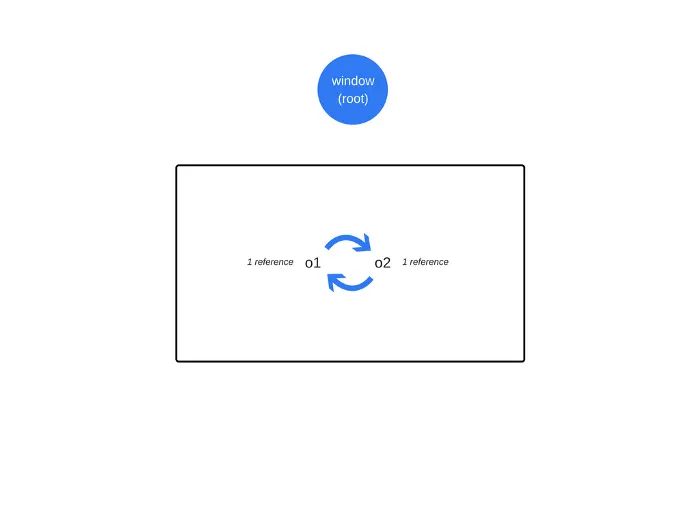
root에서 도달할 수 없는 객체이기 때문이다.
The four types of common JavaScript leaks
여기서 말하는 leak은 흔히 포너블에서 말하는 메모리 “유출”이 아닌 메모리 “누수” 이다.
1. Global variables
참고로 JS상단에 use strict 를 사용하면 해당 메모리 leak를 방지할 수 있다.
JS는 선언되지 않은 변수를 처리할때 전역 변수에 새로운 변수를 생성한다.
즉,
function foo(arg) {
bar = "some text";
}
JavaScript
복사
은 다음과 동일하다고 할 수 있다.
function foo(arg) {
window.bar = "some text";
}
JavaScript
복사
bar의 목적이 함수 내의 지역변수 사용이었다면, 필요없는 전역 변수 할당이 생성된것이다.
2. Timers or callbacks that are forgotten
자바스크립트에서 많이 사용되는 setInterval을 예로 들어보겠다.
옵저버를 제공하는 라이브러리나 콜백을 받는 함수들을 보면 대부분 객체가 닿을 수 없는 상태가 되면 이들에 대한 참조도 닿을 수 없도록 해주고 있다.
하지만 다음 코드의 경우를 보자:
var serverData = loadData();
setInterval(function() {
var renderer = document.getElementById('renderer');
if(renderer) {
renderer.innerHTML = JSON.stringify(serverData);
}
}, 5000); // 매 5초 마다 실행
JavaScript
복사
renderer객체는 어느 시점에 다른 것으로 대체되거나 제거될 수 있으며 그러면 인터벌 핸들러로 둘러쌓은 코드는 더 이상 필요 없게 된다.
이 인터벌 타이머는 아직 활성 상태이므로 가비지컬렉터는 이 핸들러나 그 내부의 것들을 가져가지 않는다. 결국은 많은 양의 데이터를 저장하고 처리하고 있을 serverData도 가져가지 않게된다.
하지만 현대적 브라우저들은 이러한 순환참조를 탐지하고 적절히 처리하는 가비지컬렉터를 지원하기 때문에 해당 문제로 인한 memory leak은 해결되었다.
3. Closures
JS에서 클로져는 자신을 감싸는 함수의 변수에 접근할 수 있는 내부 함수를 말한다. 이런 JS의 런타임 특성은 다음과 같은 메모리leak을 일으킬 수 있다:
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing)
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log("message");
}
};
};
setInterval(replaceThing, 1000);
JavaScript
복사
일단 replaceThing이 호출 되면 theThing은 커다란 배열과 새로운 클로져(someMethod)를 포함하는 새로운 객체를 얻게 된다. 아직 originalThing은 unused변수가 갖고 있는 클로져에 의해 참조되고 있다(which is theThingvariable from the previous call to replaceThing). 기억할 점은 한 번 동일한 부모 스코프에 있는 클로져들에 대한 스코프가 생성되고 나면 이것은 공유된다는 점이다.
위의 경우 someMethod 클로져를 위해 생성된 스코프는 unused와 공유되었다. unused는 originalThing에 대한 참조를 가지고 있다. unused가 다시 사용되지 않아도 someMethod는 theThing을 통해 replaceThing의 스코프 바깥에서 사용될 수 있다. 그리고 someMethod는 unused와 클로져 스코프를 공유하기 때문에 unused가 originalThing에 대해 갖고 있는 참조로 인해 강제로 활성 상태가 유지된다.
해당 내용이 이해가 가지 않는다면 : link
4. Out of DOM references
DOM노드를 데이터 구조 속에 저장하는 경우가 있다. 각 열에 대한 참조를 딕셔너리나 배열에 저장하면 동일한 DOM요소에 두 개의 참조가 존재하는것이다.(DOM tree, dictionary)
var elements = {
button: document.getElementById('button'),
image: document.getElementById('image')
};
function doStuff() {
elements.image.src = 'http://example.com/image_name.png';
}
function removeImage() {
// The image is a direct child of the body element.
document.body.removeChild(document.getElementById('image'));
// At this point, we still have a reference to #button in the
//global elements object. In other words, the button element is
//still in memory and cannot be collected by the GC.
}
JavaScript
복사
5. Event Loop and Async Programming
The building blocks of a JavaScript
일반적인 개발자가 JS application을 단일 .js 파일에 작성하면, 프로그램은 몇개의 코드블럭으로 작성될 것 이다. 그리고 코드블럭중 하나가 실행되면, 해당 프로세스가 끝난 후에 다음 프로세스가 시작될 것 이다.
하지만 JS는 보통 정의에 의해(default가 async임) 비동기적으로 작동되는것을 알아야 한다.
다음 예시를 보면:
var response = ajax('https://example.com/api');
console.log(response);
JavaScript
복사
표준 Ajax 요청은 동기식으로 작동하지 않기 때문에 console.log(response) 는 none을 반환할 것 이다.
따라서 비동기 함수의 리턴을 대기하기 위해 콜백이라는 함수를 사용한다.
ajax('https://example.com/api', function(response) {
console.log(response); // `response` is now available
});
JavaScript
복사
Implement of Asyncronize in browser
JS에서는 실제로 비동기 코드를 사용하고 있음에도 불구하고 ES6까지 JS자체에는 비동기성에 대한 직접적 concept이 내장되어 있지 않았다.
(앞에서도 언급했듯이 v8 프로세스는 싱글 스레드 이므로 한번의 하나의 프로세스만 처리한다.)
따라서 비동기 구현을 위해 브라우저에서 Web APIs, Event Table, Callback Queue, Event Loop 등을 사용한다.
•
Web APIs : DOM, AJAX, setTimeout등 브라우저가 제공하는 API.
•
Event Table : 특정 event가 발생했을때 호출할 callback을 관리하는 자료구조.
•
Callback Queue : 이벤트 발생시 호출할 callback이 추가되는 공간.
•
Event Loop : Call Stack과 Callback Queue를 감시하여, Call Stack이 비어있을 경우 Callback Queue에서 함수를 꺼내 Call Stack에 push.
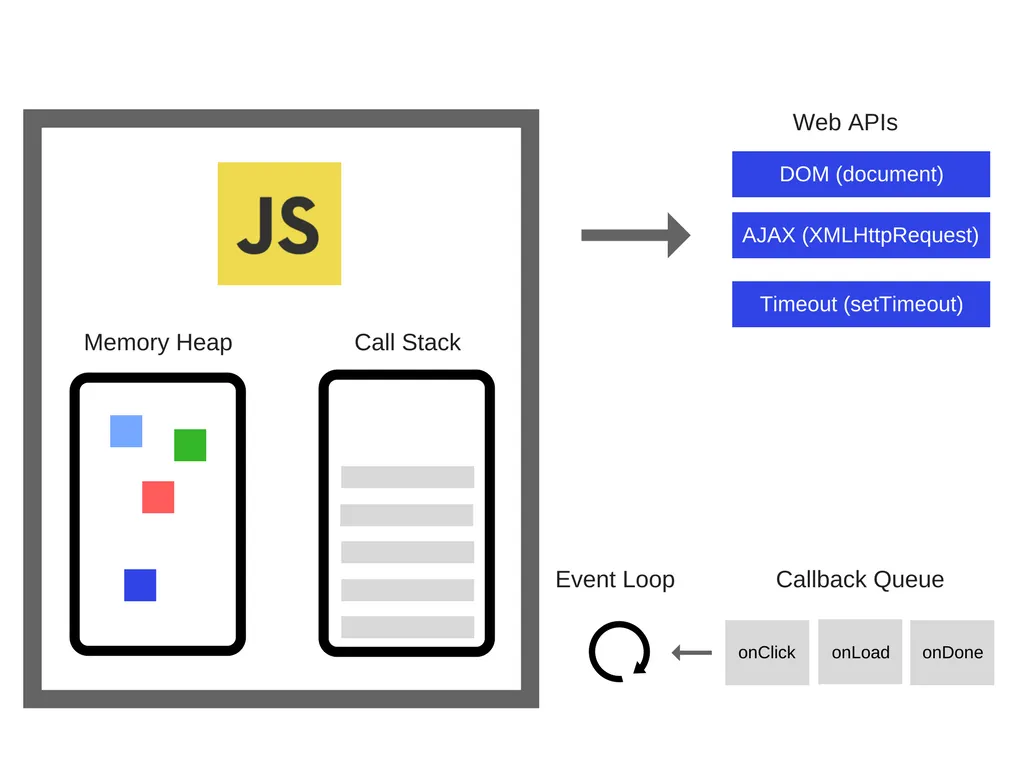
다음 예시 코드를 통해 비동기 처리과정을 알아보자:
console.log('Hi');
setTimeout(function cb1() {
console.log('cb1');
}, 5000);
console.log('Bye');
JavaScript
복사
1.
초기상태(모두 비어있음)
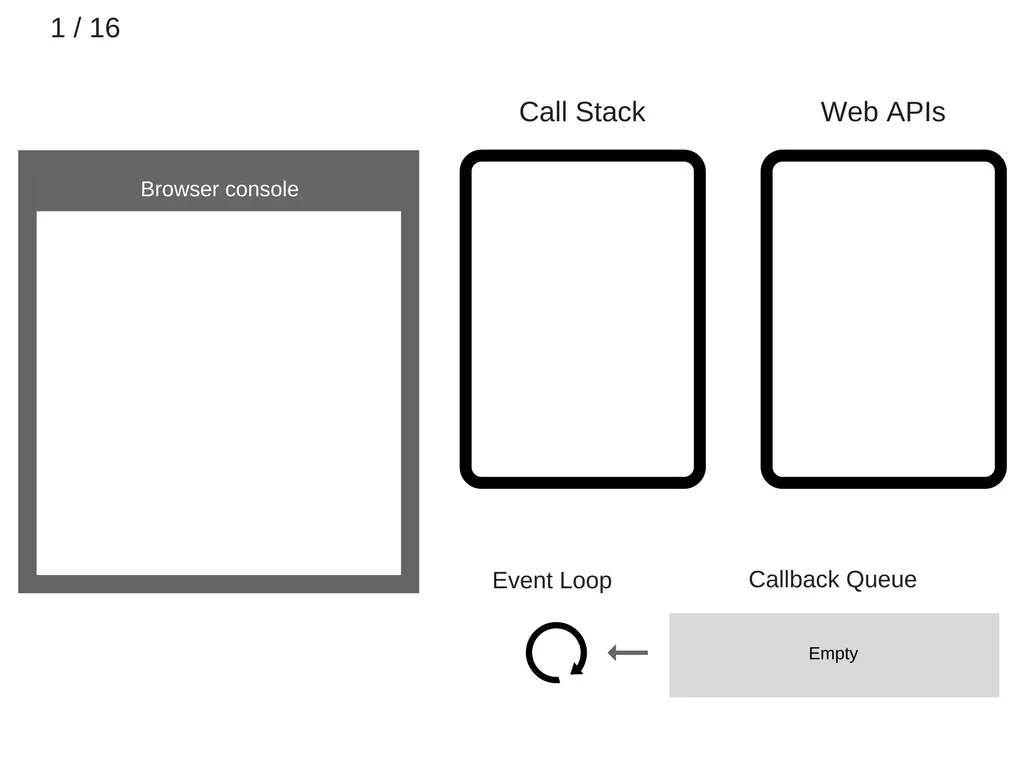
2.
console.log(’hi’)가 call stack에 추가된다.
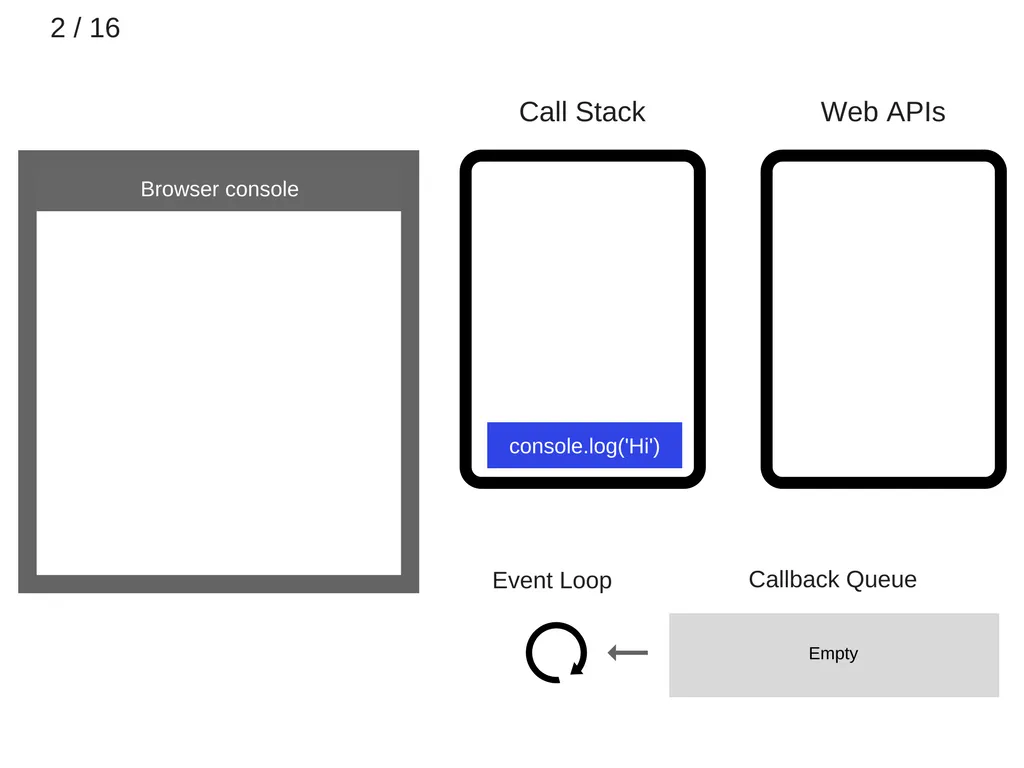
3.
console.log(’hi’)가 실행된다.
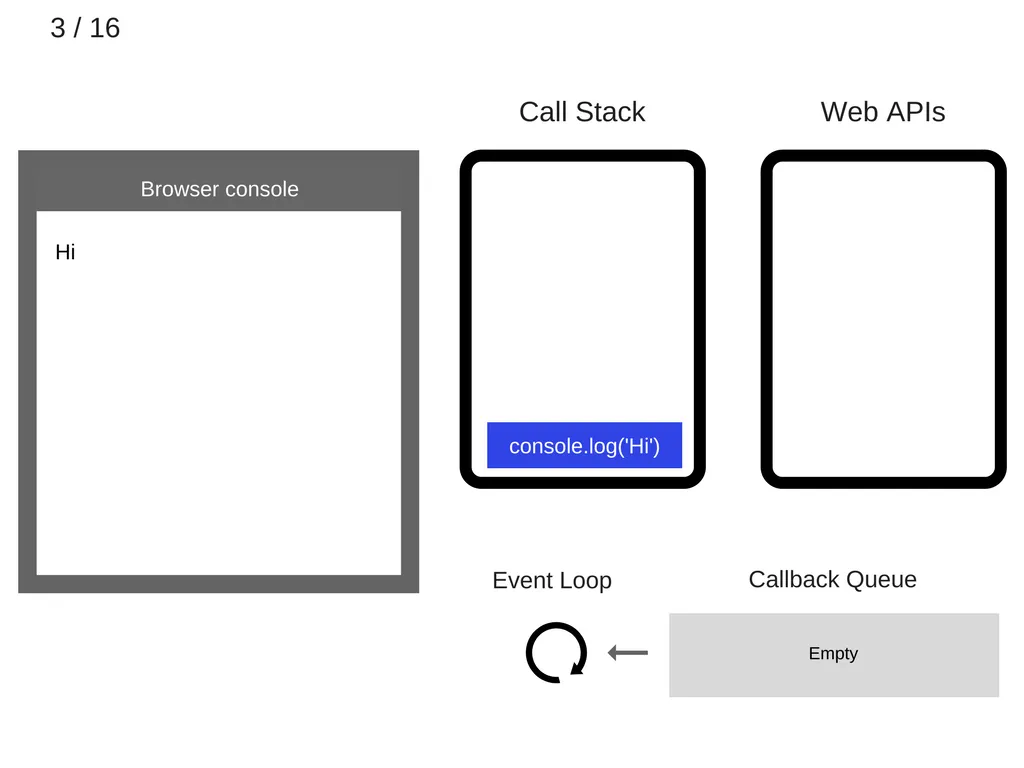
4.
console.log(’hi’)가 call stack에서 제거된다.
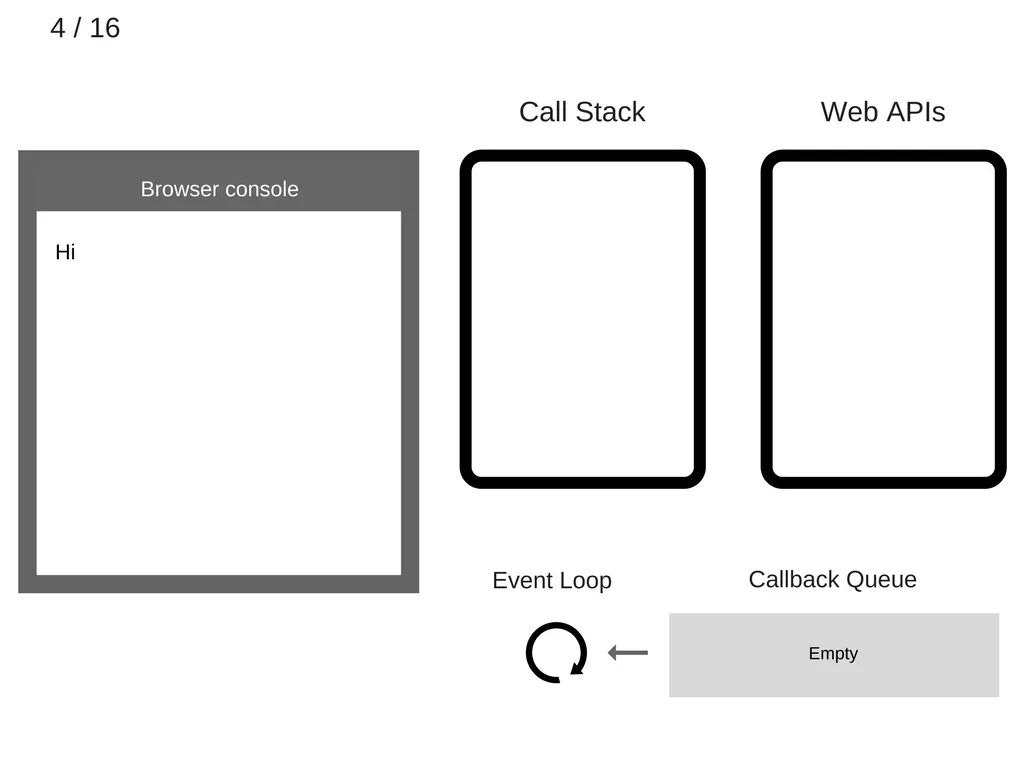
5.
setTimeout(function cb1() { ... }) 가 call stack에 추가된다.
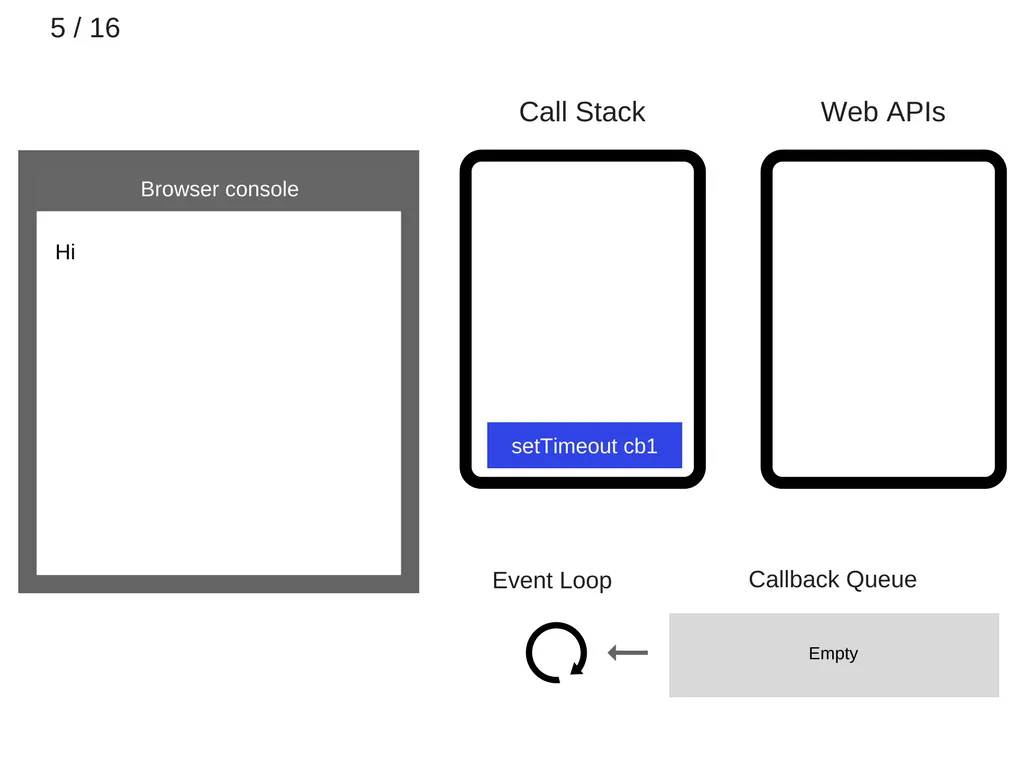
6.
setTimeout(function cb1() { ... }) 가 실행된다. 이때 브라우저는 Web API를 이용해 타이머를 생성한다.(Web API는 별도의 스레드에서 작동한다.)
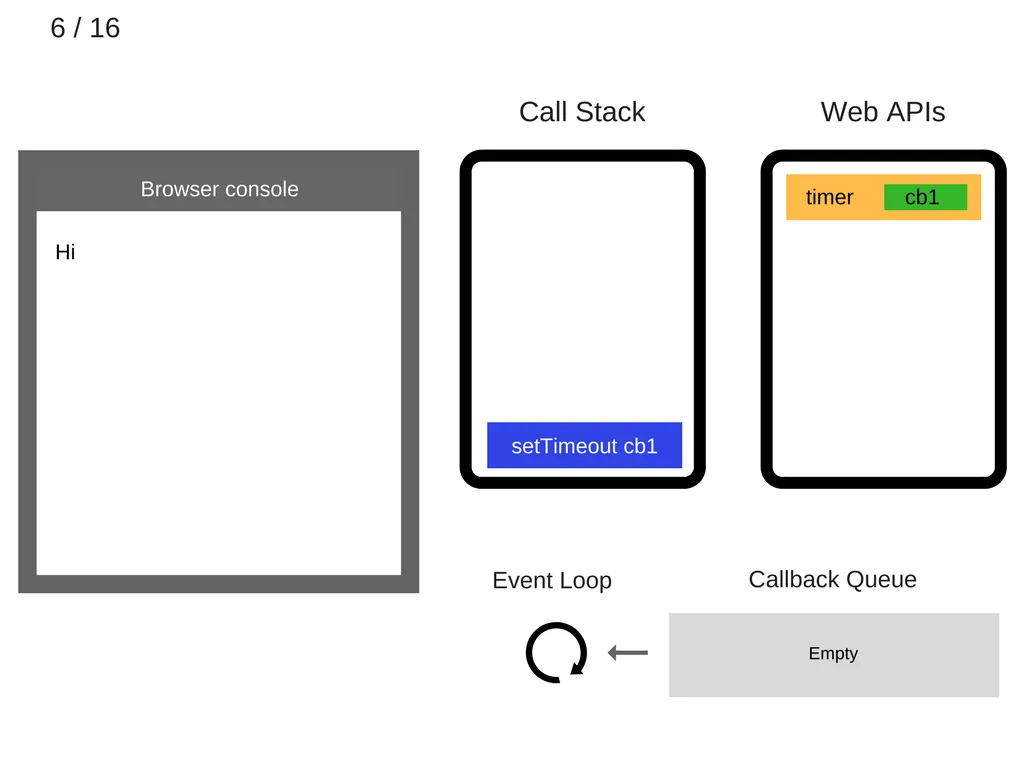
7.
setTimeout(function cb1() { ... }) 가 종료되고 call stack에서 제거된다.
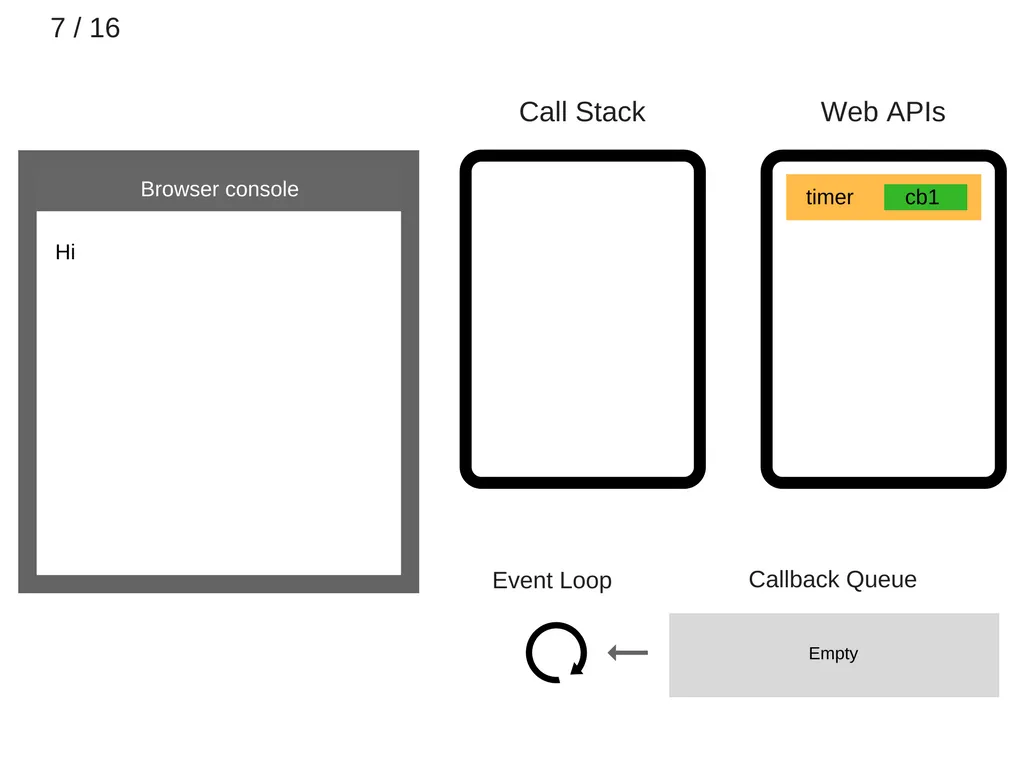
8.
console.log(’bye’)가 call stack에 추가된다.
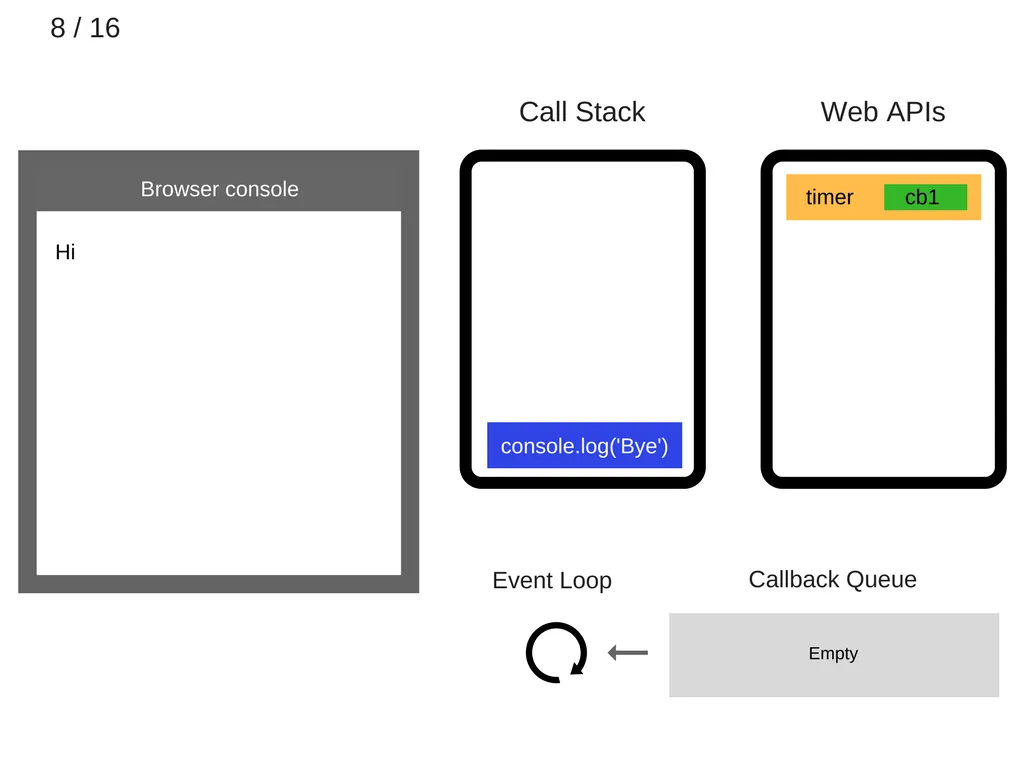
9.
console.log(’bye’)가 실행된다.
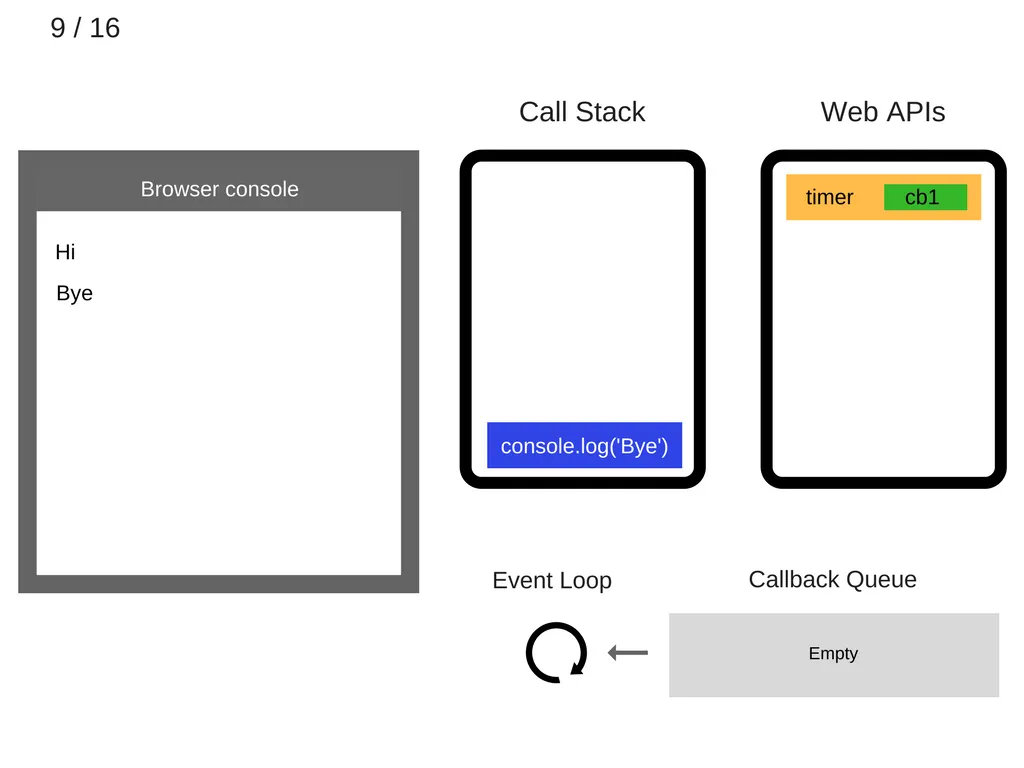
10.
console.log(’bye’)가 종료되고, call stack에서 제거된다.
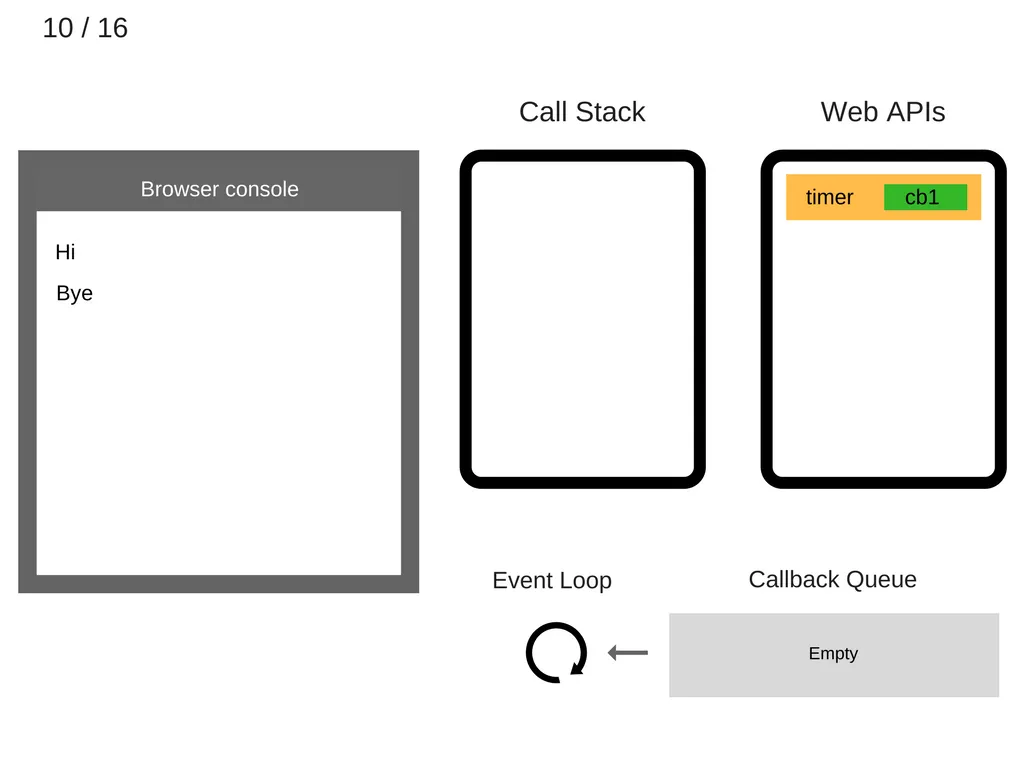
11.
최소 5000ms 후에 타이머가 종료되고, Callback Queue에 cb1을 push한다.
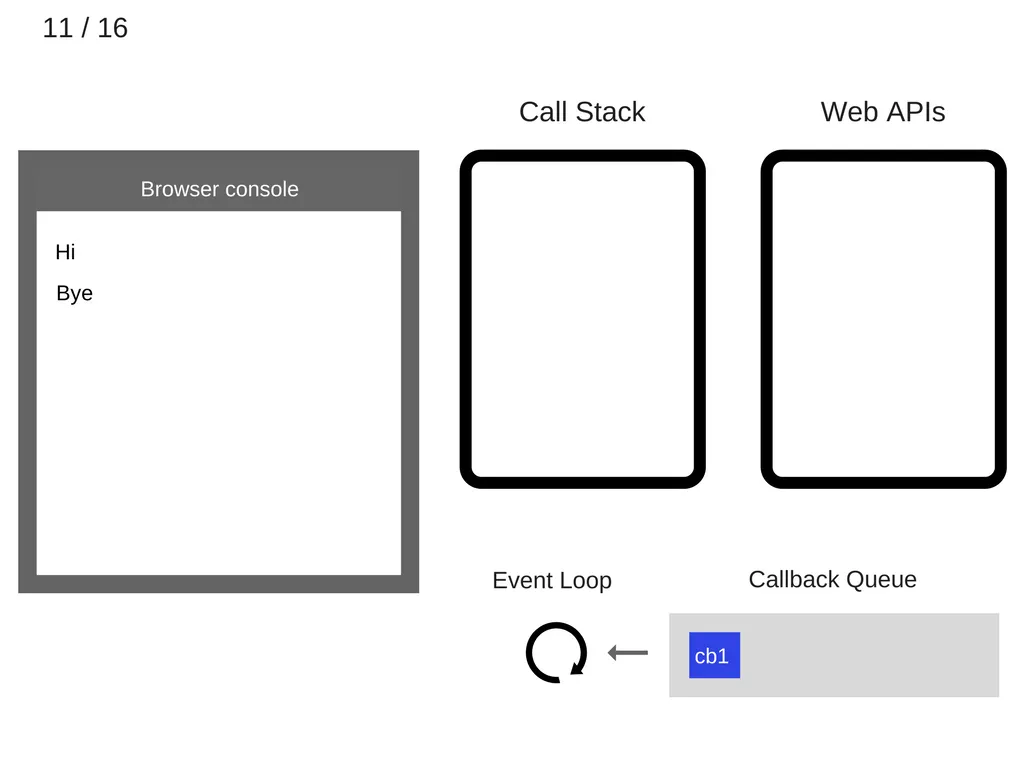
12.
event loop가 cb1콜백을 call stack으로 push한다.
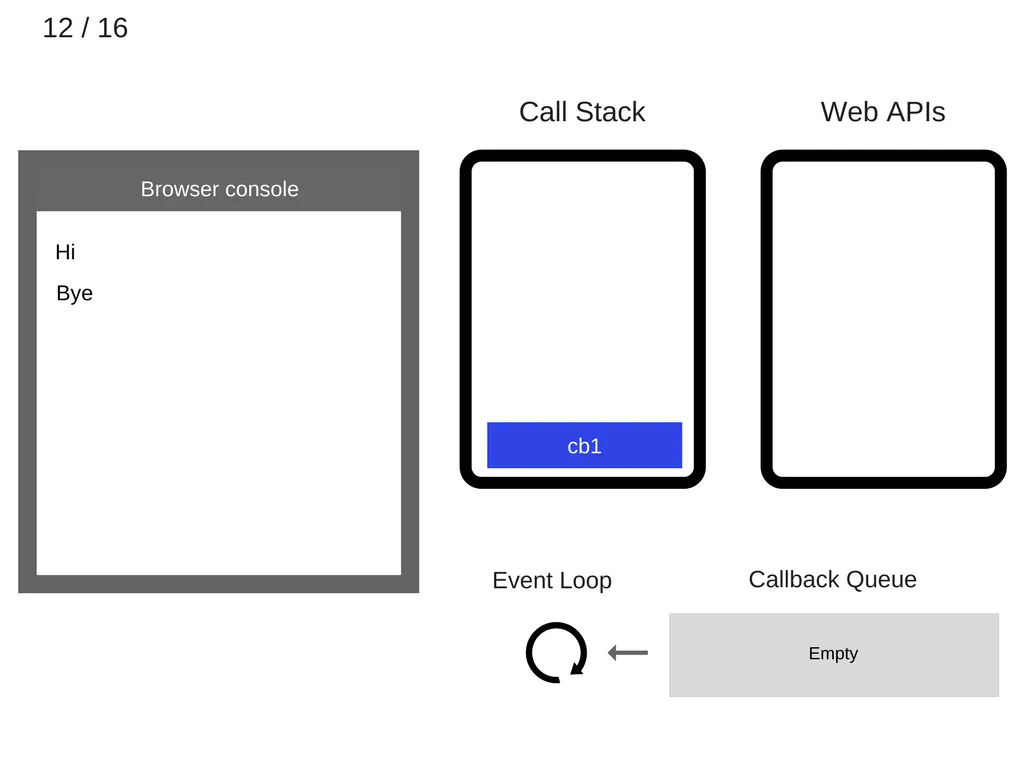
13.
cb1이 실행되고, console.log(’cb1’)이 call stack에 추가된다.
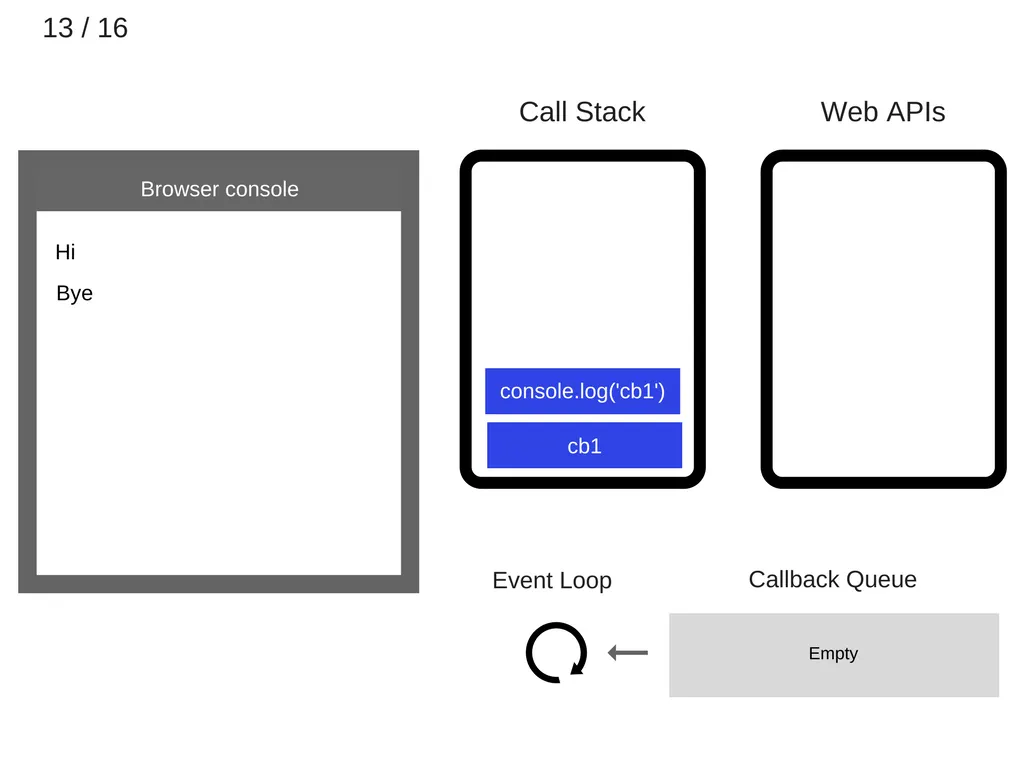
14.
console.log(’cb1’)가 실행된다.
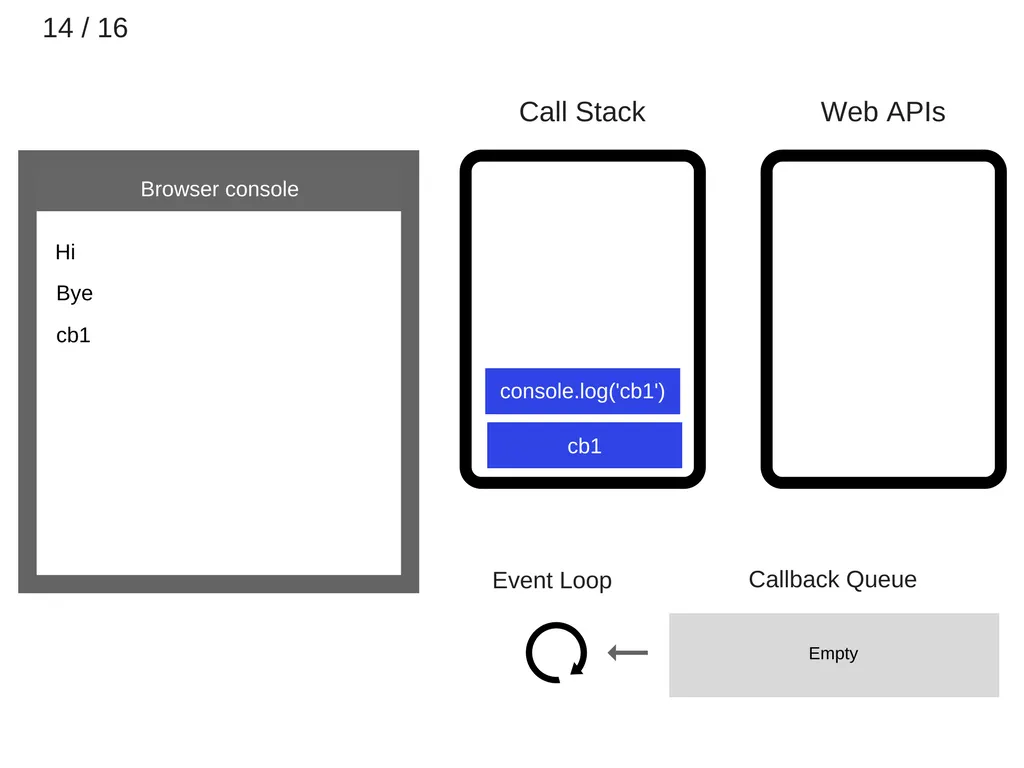
15.
console.log(’cb1’)가 종료되고, call stack에서 제거된다.
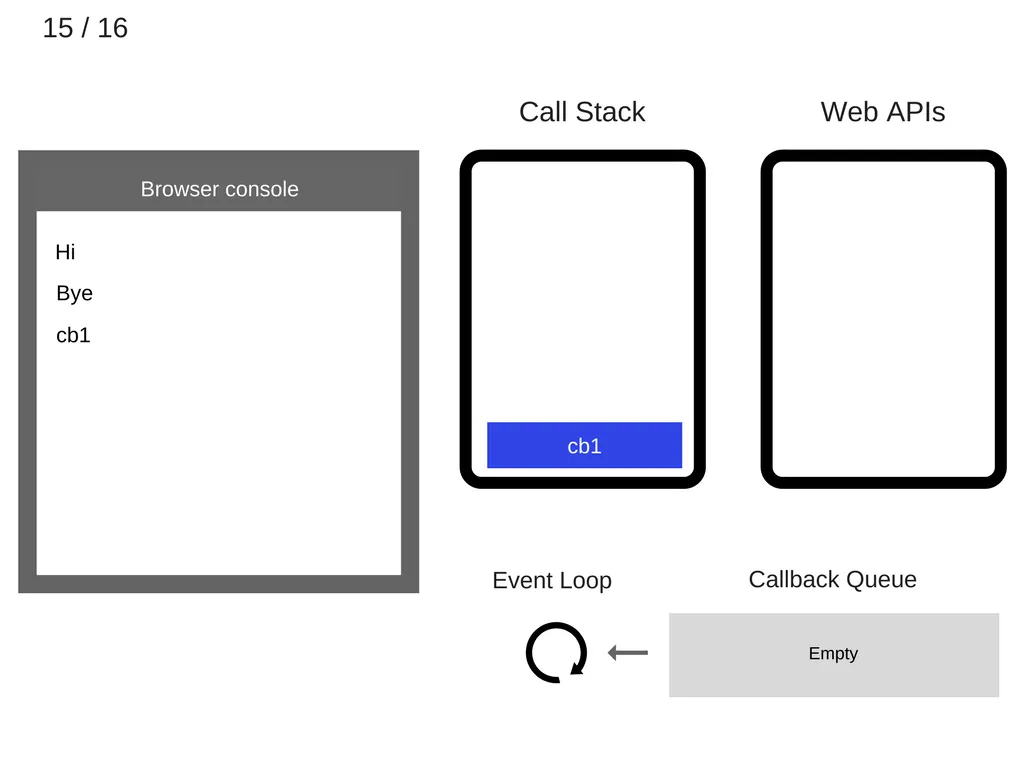
16.
cb1 이 종료되고 call stack에서 제거된다.
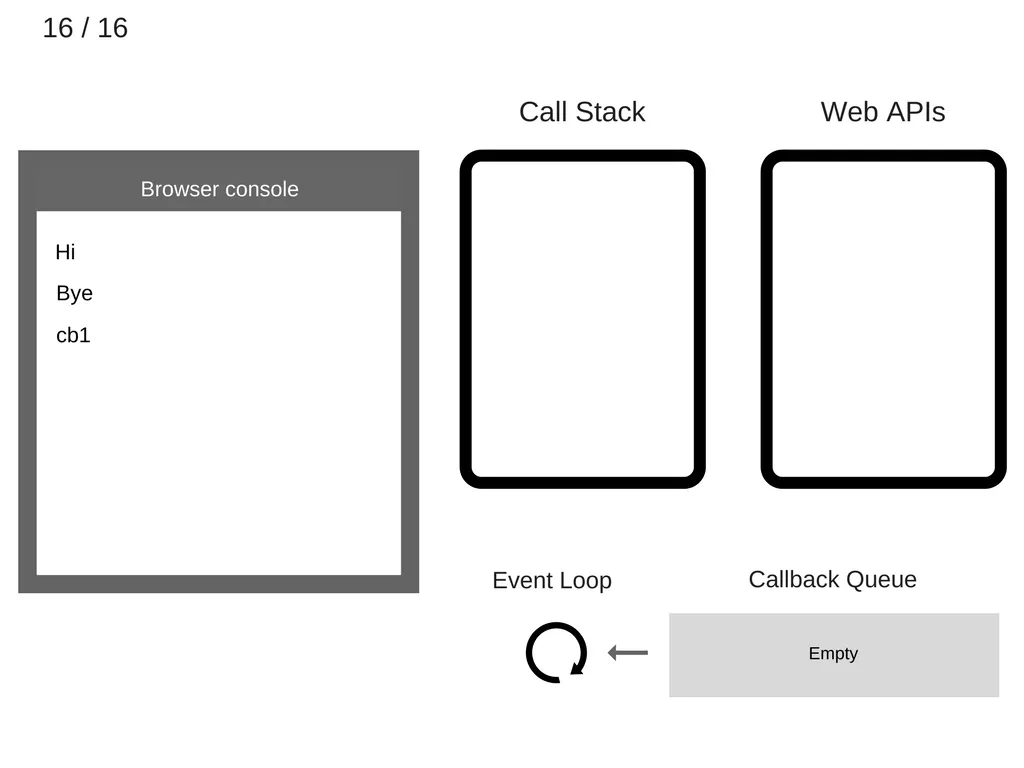
요약:

ECMAScript6
Job Queue
ES6에서는 “Job Queue”라는 개념이 도입되었는데, 기본적으로 event loop에 의해 처리되는 Callback Queue와 비슷하게 작동하지만, Callback Queue보다 높은 우선순위를 가져, event loop는 Job Queue의 작업을 우선적으로 모두 처리하고 Callback Queue를 처리한다.
Promise
Promise는 JS에서 비동기 처리에 사용되는 객체이다. 기본적으로 JS 비동기 처리시에 사용되는 콜백을 줄이는데 용이하다.
다음 예시를 보면서 이해해보자:
function sum(getX, getY, callback) {
var x, y;
getX(function(result) {
x = result;
if (y !== undefined) {
callback(x + y);
}
});
getY(function(result) {
y = result;
if (x !== undefined) {
callback(x + y);
}
});
}
// A sync or async function that retrieves the value of `x`
function fetchX() {
// ..
}
// A sync or async function that retrieves the value of `y`
function fetchY() {
// ..
}
sum(fetchX, fetchY, function(result) {
console.log(result);
});
JavaScript
복사
fetchX()와 fetchY() 의 리턴을 “미래의 값”으로 간주해 처리하는 방식을 사용해 덧셈 후 console.log를 처리하는 코드이다.(이런식의 코딩을 반복하면 콜백 지옥에 빠지게 된다..)
반면 promise 객체를 이용한 예시를 확인해보자:
function sum(xPromise, yPromise) {
// `Promise.all([ .. ])` takes an array of promises,
// and returns a new promise that waits on them
// all to finish
return Promise.all([xPromise, yPromise])
// when that promise is resolved, let's take the
// received `X` and `Y` values and add them together.
.then(function(values){
// `values` is an array of the messages from the
// previously resolved promises
return values[0] + values[1];
} );
}
// `fetchX()` and `fetchY()` return promises for
// their respective values, which may be ready
// *now* or *later*.
sum(fetchX(), fetchY())
// we get a promise back for the sum of those
// two numbers.
// now we chain-call `then(...)` to wait for the
// resolution of that returned promise.
.then(function(sum){
console.log(sum);
});
JavaScript
복사
fetchX()와 fetchY() 를 직접 호출한다. 각 함수의 리턴값은 당장 사용할 수 있을수도 있고, 없을수도 있지만 promise에서는 동일하게 취급한다.
Promise.all([xPromise, yPromise])를 호출하면 각 xPromise, yPromise가 처리된 후 then이 처리되고, then 메서드는 또 다른 promise를 생성하기 때문에 코드 마지막줄의 then은 전자 then의 promise에 대한것이다.
(이러한 코드 패턴을 promise chaining 이라고 한다.)
프로미스의 then호출은 두개의 함수를 인자로 받는데, 하나는 fulfil, 하나는 reject이다.
sum(fetchX(), fetchY())
.then(
// fullfillment handler
function(sum) {
console.log( sum );
},
// rejection handler
function(err) {
console.error( err ); // bummer!
}
);
JavaScript
복사
ECMAScript8
Async/Await
JS ES8에서는 promise사용을 쉽게 해주는 async/await
을 도입했다.
먼저 async 함수 선언을 통해 비동기 함수를 정의한다. 이렇게 생성된 함수는 AsyncFunction 객체를 반환한다. 해당 객체는 함수 내에 포함되어 있는 코드를 수행하는 비동기 함수를 나타냅니다.
이렇게 만들어진 비동기 함수가 호출 되면 이것은 프로미스를 반환한다. 비동기 함수가 프로미스가 아닌 값을 반환하면, 프로미스는 자동으로 생성되며 해당함수로 부터 반환 받은 값을 이행한다. 이 async 함수가 예외를 던지면 프로미스는 그 던져진 값과 함께 거절된다.
async 함수는 await 구문을 포함할 수 있는데 이를 이용하면 함수의 수행을 멈추고 프로미스의 이행 값이 넘어오기를 기다렸다가 async 함수의 수행을 계속해서 이어가다가 마지막에는 이행된 값을 반환할 수 있다.
다음의 예시를 보면 promise1과 promise2의 값을 보장하는것을 확인할 수 있고, 리턴형태는 promise객체인것을 확인할 수 있다.
async function loadData() {
// `rp` is a request-promise function.
var promise1 = rp('https://api.example.com/endpoint1');
var promise2 = rp('https://api.example.com/endpoint2');
// Currently, both requests are fired, concurrently and
// now we'll have to wait for them to finish
var response1 = await promise1;
var response2 = await promise2;
return response1 + ' ' + response2;
}
// Since, we're not in an `async function` anymore
// we have to use `then`.
loadData().then(() => console.log('Done'));
JavaScript
복사
또한 async function expression 을 사용해 함수명을 생략할 수 도 있다.
var loadData = async function() {
// `rp` is a request-promise function.
var promise1 = rp('https://api.example.com/endpoint1');
var promise2 = rp('https://api.example.com/endpoint2');
// Currently, both requests are fired, concurrently and
// now we'll have to wait for them to finish
var response1 = await promise1;
var response2 = await promise2;
return response1 + ' ' + response2;
}
JavaScript
복사
6. WebAssembly
WebAssembly는 웹을 위한 효율적인 저수준 바이트코드이다.
WASM을 사용하면 JavaScript 이외의 언어(예: C, C++, Rust 또는 기타)를 사용하고 그 안에 프로그램을 작성한 다음 WebAssembly로 컴파일 할 수 있다. 그 결과 로딩 및 실행이 매우 빠른 웹 앱 구현이 가능하다.
Loading
텍스트 형식인 .js를 로드하는 JS와 달리 WASM은 컴파일된 바이너리 형식 wasm 파일을 전송해 로드해 훨씬 빠른 로딩을 보여준다.
Execution
V8에서 WASM을 로드하는 과정을 알아보자:
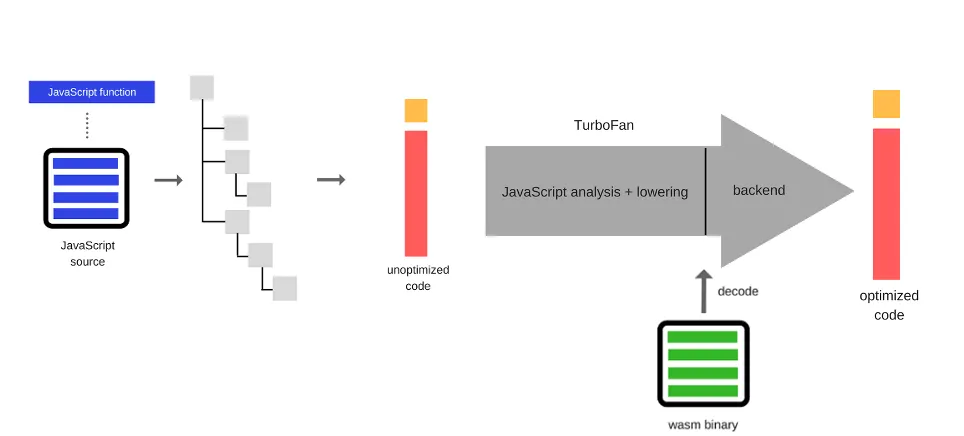
위에서 설명했던 JS 실행과정과 달리 모든 최적화가 적용된 컴파일된 바이트 코드를 실행하기 때문에 파싱, 최적화, 컴파일 등의 과정이 생략된다.
WASM과 관련된 내용은 추가될 예정.
JavaScript
복사